Time series forecasting powers critical decisions across industries—from predicting electricity demand and traffic congestion to estimating disease spread and stock trends. Yet, for years, researchers and engineers have struggled with inconsistent benchmarks that make it hard to fairly compare forecasting methods. Enter TFB (Time Series Forecasting Benchmark): an open-source, automated benchmark designed to bring fairness, reproducibility, and comprehensiveness to the evaluation of time series models.
Unlike traditional benchmarks that suffer from narrow dataset coverage, methodological bias, or inflexible evaluation pipelines, TFB tackles these issues head-on. Whether you’re comparing a classic statistical model like ARIMA to a modern deep learning architecture like PatchTST, TFB ensures both are evaluated under identical, rigorously controlled conditions—so you can trust the results.
Why Traditional Benchmarks Fall Short
Before TFB, many time series benchmarks exhibited three key flaws:
- Limited domain coverage: Most used only a handful of datasets from similar domains (e.g., energy or traffic), making conclusions brittle and non-generalizable.
- Bias against traditional methods: Deep learning approaches often received disproportionate attention, while well-established statistical or machine learning models were underrepresented or poorly tuned.
- Inconsistent evaluation pipelines: Subtle implementation choices—like discarding the last batch of test samples (the “drop-last” bug)—led to unfair comparisons and irreproducible results.
These issues made it difficult to know whether a model truly outperformed another—or simply benefited from a favorable evaluation setup.
How TFB Fixes These Problems
TFB directly addresses these shortcomings through four core innovations:
1. Broad, Real-World Dataset Coverage
TFB includes 8,068 univariate time series and 27 multivariate datasets spanning 10 diverse domains: traffic, electricity, energy, environment, nature, economics, stock markets, banking, health, and the web. This diversity ensures models are tested under a wide range of real-world conditions—not just in narrow, idealized scenarios.
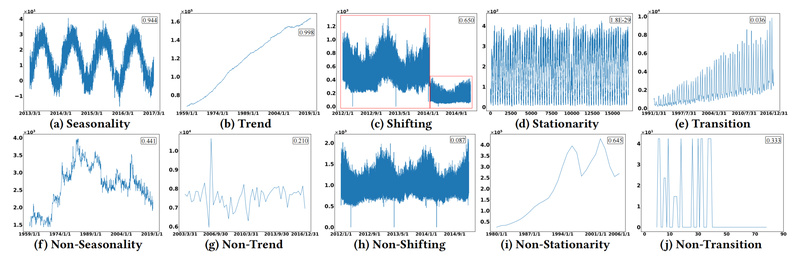
To further guarantee representativeness, TFB provides time series characterization metrics (e.g., trend, seasonality, stationarity, correlation), allowing users to understand dataset properties and avoid cherry-picking.
2. Inclusive Method Selection
Rather than favoring deep learning, TFB integrates a balanced mix of statistical, machine learning, and deep learning methods—21 univariate and 14 multivariate models in total. This includes everything from DLinear and FEDformer to PatchMLP and DUET, ensuring no method is unfairly advantaged or overlooked.
3. A Fair, Reproducible Evaluation Pipeline
TFB’s pipeline is built to eliminate subtle sources of bias. Most notably, it avoids the “drop-last” bug during testing—a common pitfall where incomplete batches are discarded, leading to inconsistent test-set usage across models. By preserving all test samples regardless of batch size, TFB ensures every method is evaluated on the exact same data.
Additionally, all experiments use locked dependency versions (via requirements-docker.txt) to guarantee reproducibility—a critical feature often missing in other libraries.
4. Support for Both Univariate and Multivariate Forecasting
TFB handles both forecasting paradigms at scale. For multivariate tasks, it even supports predicting only a subset of input variables, a practical requirement in many real-world applications (e.g., forecasting only electricity load while using weather as auxiliary input).
Real-World Impact: Who Should Use TFB?
TFB is ideal for:
- Researchers developing new forecasting algorithms who need a trustworthy baseline for comparison.
- ML engineers evaluating models before deployment in production systems.
- Product teams making data-driven decisions about which forecasting approach to adopt.
- Students and educators seeking a standardized, well-documented environment for learning and experimentation.
If your work demands fairness, cross-domain robustness, and reproducibility, TFB provides the infrastructure to make confident, evidence-based choices.
Getting Started Is Simple
TFB is designed for ease of use without sacrificing rigor:
- Install via pip (Python 3.8 recommended) or Docker:
pip install -r requirements-docker.txt
- Download preprocessed datasets and place them in the
./datasetfolder. - Run a pre-configured experiment script—e.g., to reproduce DLinear on the ILI (influenza) dataset:
sh ./scripts/univariate_forecast/ILI_script/DLinear.sh
All scripts, hyperparameters, and results are publicly available, and performance is tracked on the OpenTS-Bench leaderboard—a live, community-accessible resource for comparing model performance across time.
Limitations to Keep in Mind
While TFB sets a new standard for forecasting benchmarks, it has boundaries:
- It requires Python 3.8 for full reproducibility.
- It focuses exclusively on forecasting, not other time series tasks like anomaly detection or classification (though the team has separately open-sourced TAB for anomaly detection).
- Exact reproduction of published results depends on using the provided Dockerized environment and scripts.
These constraints ensure scientific rigor—but users should plan accordingly.
How TFB Fits Into Your Workflow
Integrating TFB into your project is straightforward:
- Use it to benchmark your own model against 20+ established baselines.
- Leverage the OpenTS leaderboard to track your method’s performance over time.
- Evaluate custom datasets using TFB’s standardized pipeline to ensure fair comparisons.
By adopting TFB, you align your work with best practices in time series evaluation—saving time, reducing bias, and increasing confidence in your results.
Summary
TFB isn’t just another benchmark—it’s a corrective framework for the entire time series forecasting community. By enforcing fairness, embracing diversity in both data and methods, and prioritizing reproducibility, TFB empowers practitioners to make decisions based on evidence, not artifacts of flawed evaluation. If you’re serious about time series forecasting, TFB belongs in your toolkit.