Large Language Models (LLMs) are transforming how we build intelligent applications—from customer service bots to clinical decision support tools. Yet one persistent and dangerous issue undermines their reliability: hallucinations. These are instances where an LLM confidently generates factually incorrect, misleading, or entirely fabricated content. In high-stakes domains like healthcare, finance, or legal advice, such errors aren’t just inconvenient—they can be costly or even harmful.
What if you could automatically assign a confidence score (from 0 to 1) to every LLM response, flagging low-confidence outputs before they reach end users? That’s exactly what UQLM delivers.
UQLM (Uncertainty Quantification for Language Models) is an open-source Python package designed to detect hallucinations using state-of-the-art uncertainty quantification (UQ) techniques. It’s not a research prototype—it’s a production-ready toolkit that integrates smoothly with LangChain and supports popular LLM providers like OpenAI, Google Vertex AI, Azure OpenAI, and local models via Ollama. Whether you’re a developer, data scientist, or product engineer, UQLM lets you enhance trust in your LLM outputs without reinventing the wheel.
Why Hallucination Detection Matters in Real Applications
Hallucinations erode user trust and can lead to serious downstream consequences. Consider:
- A medical chatbot recommending an incorrect drug dosage.
- A customer support agent giving outdated policy information.
- An enterprise assistant summarizing internal documents with fabricated details.
In each case, the model sounds confident—but it’s wrong. Traditional approaches offer no built-in mechanism to assess this risk. UQLM fills that gap by providing response-level uncertainty scores, enabling you to:
- Filter out low-confidence responses.
- Trigger human review for ambiguous answers.
- Select the most reliable output from multiple candidates.
Four Scorer Types for Every Deployment Scenario
UQLM doesn’t force a one-size-fits-all solution. Instead, it offers four flexible scorer categories, each optimized for different infrastructure, cost, and compatibility constraints:
Black-Box Scorers (Consistency-Based)
These require no access to internal model states—ideal for closed APIs like OpenAI or Anthropic. By generating multiple responses to the same prompt and measuring semantic consistency (e.g., using BERTScore or entailment probability), they estimate uncertainty.
- ✅ Works with any LLM via LangChain.
- ⚠️ Higher latency and cost due to multiple generations.
White-Box Scorers (Token-Probability-Based)
If your LLM exposes token-level probabilities (e.g., via Google Vertex AI or certain open-weight models), these scorers compute uncertainty from a single generation. Metrics include minimum token probability, sequence probability, and top-k negentropy.
- ✅ Near-zero added cost and minimal latency.
- ⚠️ Not compatible with APIs that hide internal probabilities.
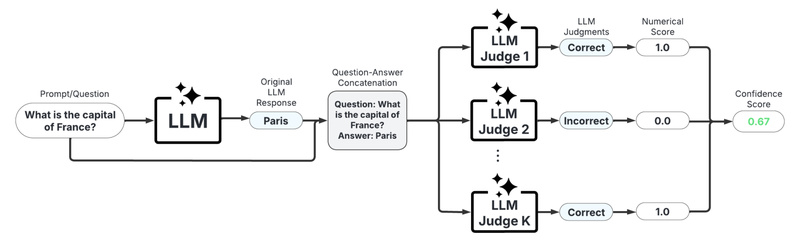
LLM-as-a-Judge Scorers
Leverage another LLM (or a panel of them) to evaluate the original response’s reliability. Highly customizable via prompt engineering and useful for nuanced tasks like fact-checking.
- ✅ Universal compatibility and high interpretability.
- ⚠️ Adds dependency on a secondary model and increases cost.
Ensemble Scorers
Combine multiple scorers into a weighted confidence score for greater robustness. Beginners can use off-the-shelf ensembles (like the “BS Detector”), while advanced users can tune weights using their own validation data.
- ✅ Best-in-class performance through fusion.
- ✅ Scales from simple plug-and-play to fine-tuned precision.
Real-World Integration Made Simple
Getting started with UQLM takes just a few lines of code. For example, using a black-box scorer with OpenAI:
from langchain_openai import ChatOpenAI from uqlm import BlackBoxUQ llm = ChatOpenAI(model="gpt-4o-mini") bbuq = BlackBoxUQ(llm=llm, scorers=["semantic_negentropy"], use_best=True) results = await bbuq.generate_and_score(prompts=["What is the capital of France?"])
The same pattern applies across White-Box, LLM-as-a-Judge, and Ensemble interfaces—with full support for Azure, Vertex AI, Ollama, and more.
Choosing the Right Scorer for Your Use Case
| Scorer Type | When to Use | Key Trade-offs |
|---|---|---|
| Black-Box | Using closed APIs (e.g., OpenAI) with no token probabilities | High cost/latency, universal compatibility |
| White-Box | Running models that expose token logits (e.g., Vertex AI, local LLMs) | Lowest cost, limited API support |
| LLM-as-a-Judge | Need explainable, context-aware evaluation; have budget for extra calls | Flexible but adds model dependency |
| Ensemble | Require maximum reliability; willing to combine signals | Tunable for experts, ready-to-use for beginners |
Practical Benefits for Teams and Builders
UQLM directly addresses common production challenges:
- Chatbots: Automatically suppress low-confidence replies or route them to human agents.
- Multi-turn workflows: Select the highest-confidence response from multiple candidates (
use_best=True). - Audit & compliance: Log confidence scores alongside outputs for traceability.
- Model monitoring: Track uncertainty trends over time to detect data drift or degradation.
Limitations and Transparent Trade-offs
UQLM is honest about constraints:
- White-Box scorers require token probabilities, which many commercial APIs don’t expose.
- Black-Box methods multiply LLM calls, increasing cost and latency.
- LLM-as-a-Judge introduces a second model’s potential biases or errors.
But by clearly documenting these trade-offs, UQLM empowers you to make informed decisions—not guesswork.
Boost Reliability with Tunable Ensembles
One of UQLM’s standout features is its ensemble scoring. You can:
- Use a pre-built ensemble (e.g., “BS Detector”) immediately.
- Or tune scorer weights using your own labeled data:
uqe = UQEnsemble(llm=llm, scorers=["exact_match", "min_probability", llm]) await uqe.tune(prompts=tuning_prompts, ground_truth_answers=ground_truth)
This allows domain-specific calibration—critical for healthcare or finance use cases.
Ready-to-Use Resources for Fast Adoption
UQLM ships with comprehensive tutorial notebooks covering:
- Black-box and white-box scoring
- LLM judge panels
- Ensemble tuning
- Multimodal uncertainty (for vision-language models)
- Score calibration to convert confidence into calibrated probabilities
Plus, full API documentation ensures smooth onboarding.
Summary
UQLM transforms uncertainty quantification from a theoretical concept into a practical engineering tool. By providing plug-and-play scorers across four complementary paradigms, it empowers teams to detect hallucinations, increase reliability, and ship safer LLM applications—without deep expertise in probabilistic modeling. Whether you’re prototyping or scaling in production, UQLM gives you the confidence to trust your LLM’s outputs—or know when not to.
Try pip install uqlm today and add a layer of trust to every LLM response.