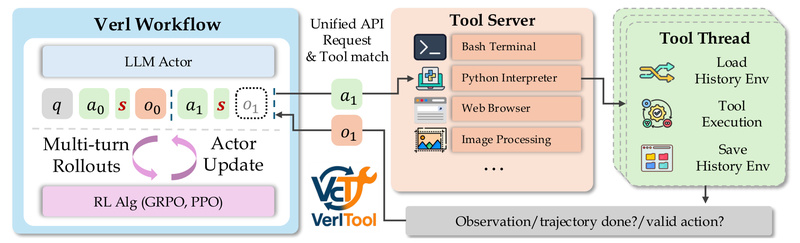
Building intelligent agents that can reason, interact with external tools, and learn from experience is a cornerstone of next-generation AI systems. Yet, existing approaches to training such agents—especially those that combine reinforcement learning (RL) with tool use—are often fragmented, inefficient, and tightly coupled to specific tasks. Enter VerlTool: an open-source, modular framework designed to unify and streamline the development of agentic reinforcement learning systems that leverage external tools across diverse domains.
VerlTool directly addresses the pain points faced by research teams and engineering groups working on tool-augmented AI: the need for a consistent infrastructure, fast training cycles, and easy extensibility without rewriting codebases for every new task. Whether you’re developing agents for SQL query generation, mathematical reasoning, visual question answering, or web-based problem solving, VerlTool provides a standardized, high-performance foundation that scales with your ambitions.
The Core Challenge: Fragmentation in Tool-Based RL
Most current implementations of Agentic Reinforcement Learning with Tool use (ARLT) are built as one-off systems. Each new task—say, code generation versus database querying—requires its own bespoke codebase with custom tool integration, environment logic, and rollout orchestration. This leads to:
- Code duplication across projects
- Synchronous execution bottlenecks that slow down training
- Limited reusability of components across modalities (text, image, code, etc.)
- High barrier to entry for new researchers or engineers
VerlTool eliminates these issues by introducing a systematic architecture that treats tools as first-class, pluggable components within a shared RL training loop.
Key Innovations That Make VerlTool Stand Out
VerlTool isn’t just another RL library—it’s a purpose-built ecosystem for multi-turn, tool-mediated agent training. Here’s what sets it apart:
1. Seamless Integration with VeRL
VerlTool is built as an extension of VeRL (Reinforcement Learning with Verifiable Rewards), inheriting its robust policy optimization infrastructure while extending it to multi-step, tool-augmented trajectories. This upstream alignment ensures compatibility with ongoing VeRL updates and reduces maintenance overhead.
2. Unified Tool API Across Modalities
Whether your agent needs to execute Python code, query a SQL database, perform a web search, or analyze an image, VerlTool exposes a standardized tool interface. Each tool is defined in a lightweight Python class and automatically integrated into the agent’s observation space via multi-modal tokens (text, image, or video). This design supports heterogeneous tool combinations within the same training run.
3. Asynchronous Rollout Execution for 2× Speedup
Traditional tool-augmented RL systems wait for every agent action and tool response before proceeding—creating idle GPU time and slow iteration cycles. VerlTool introduces trajectory-level asynchronous rollouts, decoupling actor inference from environment/tool interaction. Benchmarks show nearly 2× faster rollout generation, dramatically accelerating experimentation.
4. Plugin-First Architecture for Rapid Prototyping
Adding a new tool? Just write a Python file defining its input/output schema and logic. VerlTool’s modular plugin system handles the rest—registration, state management, and integration into the training loop. No need to modify core engine code. This lowers the barrier to exploring novel tool combinations or domains.
Where VerlTool Shines: Real-World Use Cases
VerlTool is optimized for interactive, multi-step reasoning tasks where agents must call tools repeatedly to reach a solution. It’s not designed for single-turn classification or generation—it’s built for deliberative agents. Proven domains include:
- Mathematical reasoning: Agents that write and execute code to solve complex problems
- Knowledge-intensive QA: Systems that retrieve and synthesize information from external sources
- NL2SQL: Natural language to structured database query translation with validation
- Visual reasoning: Agents that analyze images and use vision tools to answer questions
- Web automation: Agents that navigate and extract information from web pages via search or browsing tools
- Software engineering assistants: Agents that debug, test, or generate code using execution environments
In all these scenarios, VerlTool enables end-to-end RL training where rewards are assigned based on final correctness—not intermediate steps—aligning with real-world success metrics.
Getting Started: From Installation to Evaluation
VerlTool follows a developer-friendly workflow:
- Install the framework (which includes VeRL as a submodule)
- Define a tool by subclassing the base tool interface—only a few methods required
- Launch the tool server, which manages stateful interactions across trajectories
- Train using built-in recipes like ToRL or DAPO, with support for asynchronous rollouts
- Evaluate via an OpenAI-compatible API endpoint: send a question, get the final answer—tool calls are handled invisibly
The repository includes ready-to-run examples, such as Search-R1 (web search agent) and NL2SQL training pipelines, so you can validate performance on established benchmarks before building your own.
Limitations and Practical Considerations
VerlTool is powerful—but it’s not a no-code solution. Adopters should be aware of:
- Dependency on VeRL: Since VerlTool extends VeRL, users must understand its RL abstractions and keep up with submodule updates.
- RL expertise required: Effective use assumes familiarity with policy gradient methods, reward design, and trajectory logging.
- Infrastructure needs: Asynchronous speedups require proper resource allocation (e.g., separate CPU workers for tool execution).
- Not for single-turn tasks: If your problem doesn’t involve multi-step tool interaction, VerlTool’s overhead may not be justified.
That said, for teams already investing in agentic AI, VerlTool dramatically reduces development friction and accelerates innovation.
Summary
VerlTool fills a critical gap in the AI toolkit: a unified, scalable, and extensible framework for training reinforcement learning agents that use diverse external tools over multiple interaction steps. By solving the fragmentation and inefficiency of prior approaches through standardized APIs, asynchronous execution, and modular design, it empowers researchers and engineers to focus on agent capabilities—not plumbing. If you’re building next-generation reasoning agents that act, not just answer, VerlTool is worth your serious consideration.
The code is open-source and actively maintained, with comprehensive documentation and working examples to get you started today.