Video understanding has long been a bottleneck for multimodal large language models (MLLMs). While models can recognize objects or scenes in static images with high accuracy, reasoning about dynamic, time-dependent events in videos remains a significant challenge. Enter Video-R1—the first systematic effort to enhance video reasoning capabilities in MLLMs using rule-based reinforcement learning (RL).
What makes Video-R1 stand out isn’t just its performance—it achieved 35.8% accuracy on VSI-Bench, surpassing commercial giants like GPT-4o—but also its practicality. You don’t need a fleet of TPUs or proprietary infrastructure to train or deploy it. With as few as four H20 (96GB) GPUs or five A100s, teams can reproduce state-of-the-art video reasoning results using open weights, open data, and open code.
Built on the Qwen2.5-VL architecture and enhanced with vLLM support, Video-R1 offers a full-stack solution: from dataset curation and chain-of-thought (CoT) annotation to supervised fine-tuning (SFT) and temporal-aware RL training. It’s designed for engineers, researchers, and product teams who need MLLMs that don’t just “see” videos—but truly understand them over time.
Why Video Reasoning Needs a New Approach
Traditional video MLLMs often treat videos as sequences of independent frames, missing the nuanced temporal dependencies that define actions, causality, and spatial dynamics. This limits their ability to answer questions like “What caused the object to fall?” or “Did the person enter before or after the door opened?”
Video-R1 directly tackles this by introducing temporal modeling into the RL training loop—a capability missing in prior approaches. Moreover, high-quality video reasoning data is notoriously scarce. Instead of waiting for massive labeled video datasets to emerge, Video-R1 innovatively integrates high-quality image reasoning data into training, using it as a stabilizing foundation before introducing video-specific signals.
This hybrid strategy not only mitigates data scarcity but also enables a more robust cold-start via supervised fine-tuning on the Video-R1-CoT-165k dataset—where every example includes a detailed reasoning trace generated by a strong teacher model (Qwen2.5-VL-72B) and filtered for consistency.
Core Innovations That Drive Performance
T-GRPO: Temporal-Aware Reinforcement Learning
At the heart of Video-R1 is T-GRPO, a novel extension of the GRPO algorithm that explicitly encourages the model to leverage temporal information across frames. Unlike standard RL methods that optimize only for final answer correctness, T-GRPO rewards reasoning processes that reference frame transitions, object trajectories, and event ordering—effectively teaching the model how to think about time.
This leads to observable “aha moments” during inference: the model sometimes revises its initial hypothesis mid-generation after reconsidering temporal evidence, demonstrating emergent self-reflection behavior rarely seen in video MLLMs.
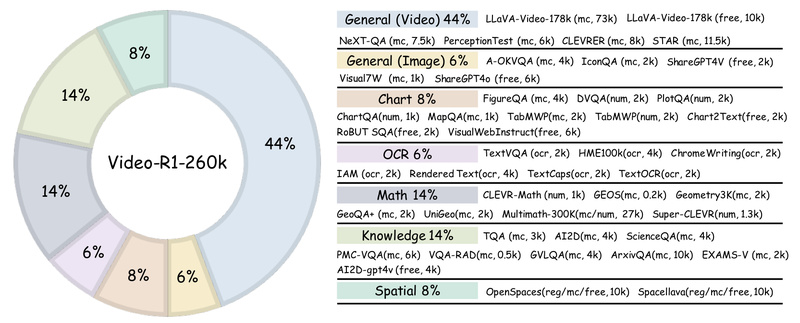
Unified Image-Video Training Pipeline
Video-R1’s training data—Video-R1-260k—combines video and image samples in a carefully balanced mix. This design choice addresses two problems at once:
- Data efficiency: Image reasoning data is abundant and high-quality, providing strong priors for logical deduction.
- Generalization: Models trained on both modalities learn transferable reasoning skills that apply even when video data is limited.
The result? A 7B-parameter model that outperforms much larger proprietary systems on specialized benchmarks like VideoMMMU, MVBench, TempCompass, and the newly introduced Video-Holmes (where it scored 36.5%, beating o4-mini and Gemini-2.0-Flash).
Practical Workflow: From Setup to Evaluation
Video-R1 ships with a complete, reproducible pipeline—a rarity in cutting-edge MLLM research. Here’s how to get started:
-
Environment Setup:
Clone the repository and install dependencies via the providedsetup.sh. The codebase requires specific versions (vLLM 0.7.2, TRL 0.16.0, and a pinned Transformers version) to ensure compatibility with Qwen2.5-VL’s video processing utilities. -
Data Preparation:
Download the curated datasets from Hugging Face. The Video-R1-CoT-165k JSON file is used for SFT; Video-R1-260k drives RL training. Both include mixed image-video samples with structured annotations. -
Training:
- Run one epoch of SFT using
run_sft_video.shto initialize the model with reasoning behaviors. - Follow with T-GRPO RL training (
run_grpo_vllm_qwen25vl.sh) for ~1,200 steps. Training uses 16 frames per video at 128×28×28 resolution per frame—keeping VRAM usage manageable on 4–5 high-end GPUs.
- Run one epoch of SFT using
-
Inference & Evaluation:
During evaluation, you can increase frame count (16/32/64) and resolution (up to 256×28×28) for better performance. The providedeval_bench.shscript automates benchmarking across all major video reasoning datasets using consistent decoding settings (top_p=0.001, temperature=0.01).
For custom use cases, inference_example.py lets you run single-sample predictions with minimal code.
Ideal Use Cases for Technical Teams
Video-R1 is particularly valuable in scenarios where reasoning over time matters more than simple recognition:
- Video QA systems for educational platforms (e.g., “Explain the steps in this chemistry experiment”).
- Industrial monitoring tools that detect procedural deviations in manufacturing or safety videos.
- Accessibility assistants that narrate dynamic scenes for visually impaired users with causal explanations.
- Research prototypes exploring embodied AI, where video understanding informs action planning.
Because it supports multiple output types—multiple choice, numerical answers, OCR extraction, free-form text, and regression—it adapts easily to diverse application requirements.
Limitations and Practical Considerations
While powerful, Video-R1 isn’t a one-size-fits-all solution:
- Training is limited to 16 frames, though inference supports more. This means it’s best suited for short-to-medium videos (e.g., <30 seconds at 1 fps).
- It’s tightly coupled with Qwen2.5-VL; integrating it into other MLLM backbones (e.g., LLaVA, InternVL) would require significant adaptation.
- RL training, while efficient relative to alternatives, still demands high-end GPUs and careful hyperparameter tuning.
- Dependency on specific library versions means you’ll need to manage your environment precisely—deviating may cause silent failures or degraded performance.
Nonetheless, for teams committed to building video-capable AI with transparent, open methods, these trade-offs are well worth the gains in reasoning fidelity.
Summary
Video-R1 redefines what’s possible for open-source video reasoning in MLLMs. By combining temporal-aware RL (T-GRPO), mixed image-video training, and a full-stack implementation, it delivers state-of-the-art performance with accessible hardware requirements. It doesn’t just match commercial models—it beats them on tasks that demand deep understanding of space and time in videos.
If your project requires an MLLM that can reason, not just recognize, Video-R1 provides a compelling, reproducible foundation to build upon. With code, models, and datasets fully released, there’s never been a better time to integrate advanced video reasoning into your workflow.