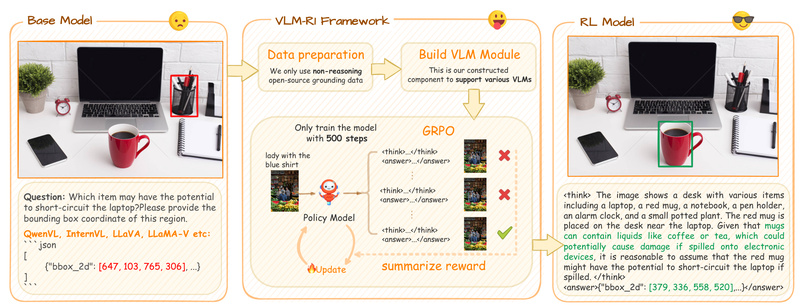
If you’re working on vision-language tasks that require precise reasoning—like identifying objects based on natural language descriptions, detecting UI defects from screenshots, or solving multimodal math problems—you know that standard supervised fine-tuning (SFT) often falls short when faced with real-world complexity or out-of-domain data. Enter VLM-R1, a novel framework that brings the power of reinforcement learning (RL) to vision-language models (VLMs), inspired by the success of DeepSeek-R1 in pure language domains.
VLM-R1 leverages rule-based rewards derived from deterministic ground-truth annotations—common in many visual understanding tasks—to train models that not only perform well on in-domain benchmarks but, more importantly, generalize robustly to unseen scenarios. The result? State-of-the-art performance on tasks like Open-Vocabulary Detection (OVD) and multimodal math reasoning, with documented advantages over traditional SFT approaches.
Best of all, VLM-R1 is fully open-source, supports flexible training setups (including LoRA and multi-node), and offers pre-trained checkpoints for immediate use. Whether you’re a researcher exploring RL for multimodal learning or an engineer building robust visual AI systems, VLM-R1 provides a practical, high-impact path forward.
Why VLM-R1 Stands Out
Superior Generalization Through Reinforcement Learning
Unlike SFT, which can overfit to training data patterns, VLM-R1 uses GRPO (Group Relative Policy Optimization)—an RL method that rewards correct outputs based on verifiable ground truth. In Referring Expression Comprehension (REC), for example, VLM-R1 shows steady performance gains as training progresses, while SFT models plateau or even degrade on out-of-domain test sets. This makes VLM-R1 especially valuable in dynamic environments where data distributions shift, such as robotics, autonomous systems, or real-world UI testing.
Multi-Task Vision-Language Excellence
VLM-R1 isn’t limited to a single use case. The project demonstrates strong results across diverse tasks:
- Open-Vocabulary Detection (OVD): Achieves state-of-the-art on OVDEval, outperforming both SFT baselines and specialized detection models.
- Multimodal Math Reasoning: Tops the OpenCompass Math Leaderboard among models under 4B parameters.
- Referring Expression Comprehension (REC): Excels at grounding language in visual scenes, even on complex out-of-domain data like LISA-Grounding.
- GUI Defect Detection: Analyzes before/after screenshots to identify UI regressions with higher accuracy and better generalization than SFT counterparts.
This versatility stems from a unified training framework that adapts to different reward structures—such as odLength, weighted_sum, or cosine—tailored to each task’s evaluation criteria.
Developer-Friendly Training and Deployment
VLM-R1 lowers the barrier to entry with:
- Multiple fine-tuning options: Full fine-tuning, LoRA, or frozen vision modules to suit varying compute budgets.
- Multi-node and multi-image support: Scale training across machines or handle inputs with multiple images (e.g., for temporal or comparative tasks).
- Broad model compatibility: Works with Qwen2.5-VL and InternVL, with clear instructions for adding new VLMs.
- Optimized inference: Thanks to integration with Huawei’s
xllmframework, VLM-R1 models now achieve 50% lower TTFT (Time to First Token) and 127% higher throughput compared to earlier vLLM-based deployments.
Hardware flexibility is also prioritized: VLM-R1 supports deployment on Huawei Ascend Atlas 800T A2 and Atlas 300I Duo series, expanding access beyond NVIDIA-centric ecosystems.
Ideal Applications for VLM-R1
VLM-R1 shines in scenarios where precision, stability, and out-of-distribution robustness are critical:
- Autonomous systems that must interpret novel visual scenes using natural language instructions (e.g., “pick up the red cup on the left”).
- Software testing automation, where models compare GUI states to detect unintended UI changes.
- Open-world object detection, where new categories emerge continuously and models must generalize from sparse labels.
- Educational AI tools that solve multimodal math problems involving diagrams, graphs, or geometric figures.
Crucially, VLM-R1 is best suited for tasks with well-defined, verifiable answers—since its RL rewards depend on deterministic ground truth. It’s less ideal for subjective or open-ended generation (e.g., image captioning with stylistic variation).
Getting Started with VLM-R1
Using VLM-R1 is straightforward:
-
Choose a pre-trained model based on your task:
VLM-R1-Qwen2.5VL-3B-OVD-0321for open-vocabulary detectionVLM-R1-Qwen2.5VL-3B-Math-0305for multimodal mathVLM-R1-Qwen2.5VL-3B-REC-500stepsfor referring expression tasks
-
Run inference using the provided checkpoints and evaluation scripts (
test_rec_r1.py, etc.). -
Fine-tune on custom data using the GRPO pipeline:
- Prepare data in a simple JSONL format with image paths and conversation-style prompts.
- Use scripts like
run_grpo_rec.sh(single-image) orrun_grpo_gui.sh(multi-image). - Customize rewards via
is_reward_customized_from_vlm_moduleif your task requires novel metrics.
Data loading supports multiple datasets and image folders via colon-separated paths, and the codebase is designed for easy debugging with enhanced training logs.
Limitations and Ongoing Work
While powerful, VLM-R1 has boundaries to consider:
- It requires tasks with deterministic ground truth to define reliable rewards. Highly subjective tasks aren’t a natural fit.
- Full fine-tuning demands significant GPU memory, though LoRA and multi-node training mitigate this.
- Cross-task generalization (e.g., training on REC and evaluating on OVD) remains an active research area, as noted in the project’s “ToDo” list.
Nonetheless, the project’s transparency—through technical reports, blogs, and ablation studies on phenomena like “reward hacking” and the “OD aha moment”—makes it a valuable resource for advancing vision-language RL.
Summary
VLM-R1 redefines what’s possible in vision-language modeling by bringing stable, reward-driven reinforcement learning to tasks with clear evaluation criteria. It doesn’t just match SFT—it surpasses it in generalization, offers state-of-the-art performance across multiple benchmarks, and provides practical tooling for real-world deployment. For teams building next-generation multimodal systems that must reason reliably beyond their training data, VLM-R1 is a compelling, open-source solution worth adopting today.