Deep reinforcement learning (DRL) holds immense promise—from robotic control and autonomous systems to multi-agent coordination and game AI. Yet for many engineers and researchers, the reality is far from ideal: implementations are scattered, results are unstable, hyperparameters behave mysteriously, and reproducing published performance often feels like chasing smoke.
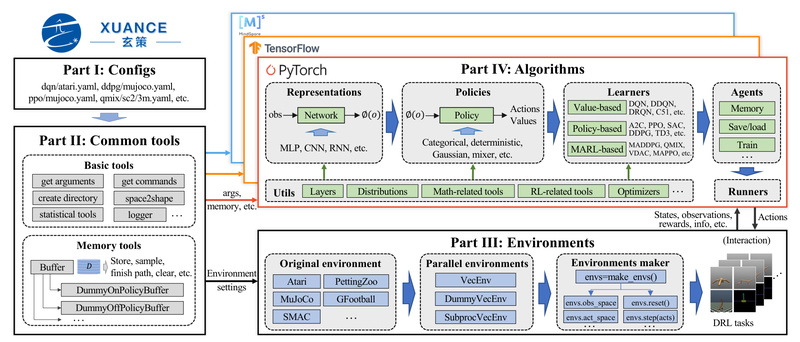
Enter XuanCe—an open-source, comprehensive, and unified DRL library built to tackle these very frustrations. Designed from the ground up for clarity, flexibility, and reproducibility, XuanCe provides high-quality, well-documented implementations of over 40 classical and modern algorithms across single-agent, multi-agent, model-based, and contrastive reinforcement learning paradigms. Most impressively, it does so while supporting PyTorch, TensorFlow 2, and MindSpore in a single codebase—without forcing you to choose one backend forever.
If you’ve ever wasted days debugging an RL pipeline or hesitated to adopt DRL due to its notorious instability, XuanCe might be the practical, production-ready foundation you’ve been looking for.
One Library, Three Frameworks—No Lock-In
Unlike most DRL libraries tied exclusively to PyTorch or TensorFlow, XuanCe is engineered for cross-framework compatibility. Whether your team uses PyTorch for rapid prototyping, TensorFlow for production deployment, or Huawei’s MindSpore for Ascend hardware acceleration, XuanCe lets you run the same algorithm with minimal code changes.
This eliminates vendor lock-in and dramatically reduces migration costs. You can train a PPO agent in PyTorch on your laptop, then re-run it on Ascend NPU clusters using MindSpore—without rewriting core logic. For organizations managing heterogeneous infrastructure or exploring multiple deep learning ecosystems, this flexibility is a strategic advantage.
Algorithm Coverage That Meets Real-World Needs
XuanCe isn’t just a toy collection of textbook algorithms. It includes battle-tested implementations across four major DRL categories:
- Single-Agent DRL: DQN variants (Double, Dueling, PER, Noisy, C51), policy gradients (A2C, PPO, SAC, TD3, DDPG), and more.
- Multi-Agent RL (MARL): QMIX, MADDPG, MAPPO, COMA, VDN—critical for cooperative or competitive agent teams in logistics, gaming, or simulation.
- Model-Based RL: DreamerV2, DreamerV3, and HarmonyDream for sample-efficient learning from pixels.
- Contrastive RL: CURL, SPR, and DrQ to improve representation learning in visual environments.
This breadth means you can prototype solutions for robotic warehouse coordination, train agents in StarCraft II via SMAC, or fine-tune control policies on MuJoCo—all within one consistent library. No more stitching together incompatible GitHub repos or reverse-engineering undocumented code.
From Idea to Result in Three Lines of Code
XuanCe’s modular, plug-and-play design drastically lowers the barrier to experimentation. Training a DQN agent on CartPole takes just three lines:
import xuance runner = xuance.get_runner(method='dqn', env='classic_control', env_id='CartPole-v1', is_test=False) runner.run()
Testing the trained model? Flip is_test=True. That’s it. Under the hood, XuanCe handles environment setup, model initialization, training loop orchestration, and logging—freeing you to focus on what to build, not how to wire it.
This simplicity is invaluable for teams under tight deadlines, students validating concepts, or researchers comparing algorithmic variants at scale.
Runs Everywhere: From Laptop to Cloud to Edge
XuanCe is built for real-world deployment diversity. It runs consistently on:
- Operating systems: Ubuntu, Windows, macOS, and EulerOS
- Hardware: CPU, NVIDIA GPU, and Huawei Ascend
- Execution modes: single-threaded, parallel environments (for faster data collection), and distributed multi-GPU training
This means your local development workflow translates seamlessly to cloud clusters or edge devices. No more “it works on my machine” surprises when moving to production.
Built-In Tools for Trust and Transparency
DRL’s reputation for instability isn’t unfounded—but XuanCe fights back with built-in diagnostics and automation:
- Automatic hyperparameter tuning: Reduce trial-and-error by leveraging integrated optimization.
- Native visualization: Log metrics to TensorBoard or Weights & Biases with zero extra code.
- Structured logging: Training curves, episode rewards, and model checkpoints are saved automatically under
./logs/.
These features help you understand why an agent succeeds or fails—critical for gaining stakeholder trust or debugging subtle reward shaping issues.
Where XuanCe Delivers the Most Value
XuanCe shines in scenarios where reproducibility, speed, and flexibility matter:
- Research labs benchmarking MARL algorithms across SMAC or MPE environments
- Startups prototyping autonomous agents for drones, logistics, or gaming
- Enterprises experimenting with DRL for process optimization but wary of fragile, unmaintainable code
It’s less ideal if you need a hyper-minimal custom implementation or are working exclusively with unpublished, cutting-edge algorithms not yet included. But for the vast majority of practical DRL use cases, XuanCe offers a robust, future-proof foundation.
Getting Started Is Deliberately Simple
Installation follows standard Python practices:
conda create -n xuance_env python=3.8 conda activate xuance_env pip install xuance[torch] # or [tensorflow], [mindspore], or [all]
Run your first experiment in seconds, consult the full documentation, or join active community channels (Discord, Slack, GitHub Discussions) for support. The barrier to validating XuanCe’s fit for your project is intentionally low.
Summary
XuanCe solves the core pain points that have long plagued applied reinforcement learning: fragmentation, instability, and framework dependency. By unifying over 40 algorithms across PyTorch, TensorFlow, and MindSpore—and pairing them with a clean API, cross-platform support, and built-in tooling—it turns DRL from a research curiosity into a practical engineering asset. Whether you’re exploring agent-based simulation, optimizing robotic control, or scaling multi-agent systems, XuanCe gives you a reliable, reproducible, and flexible starting point.