End-to-end autonomous driving systems promise a streamlined alternative to traditional modular pipelines—where perception, prediction, and planning are handled by separate…
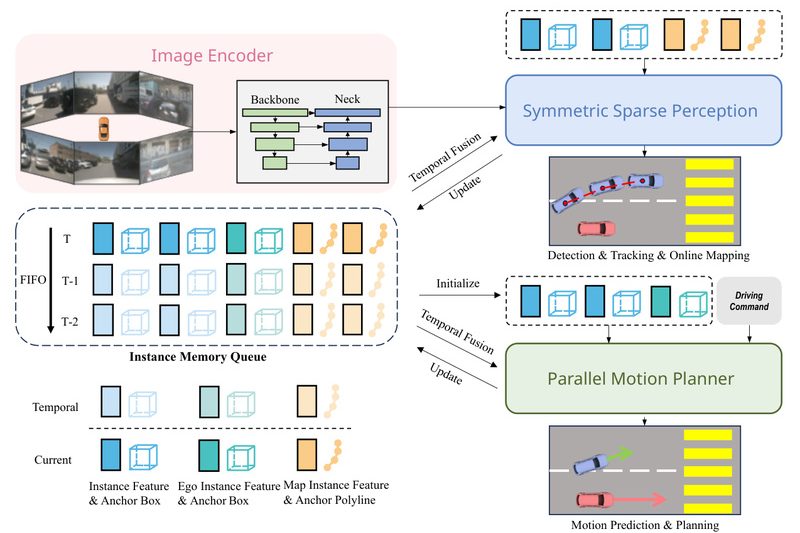
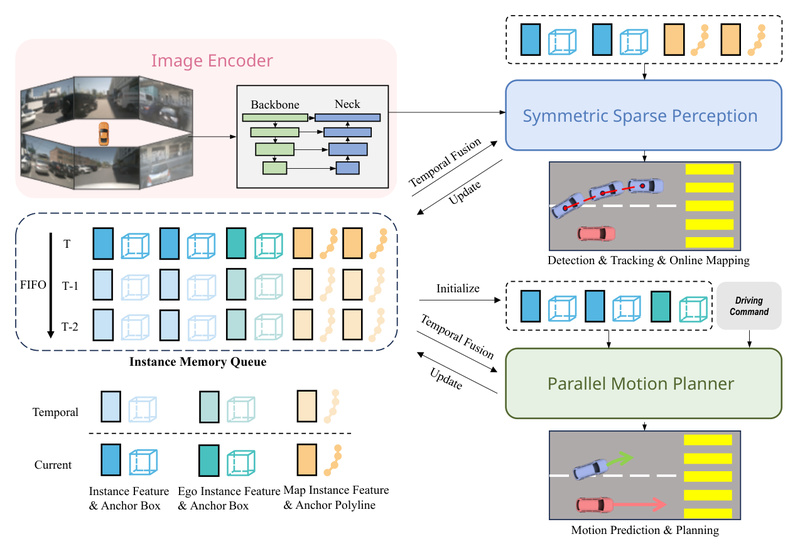
End-to-end autonomous driving systems promise a streamlined alternative to traditional modular pipelines—where perception, prediction, and planning are handled by separate…
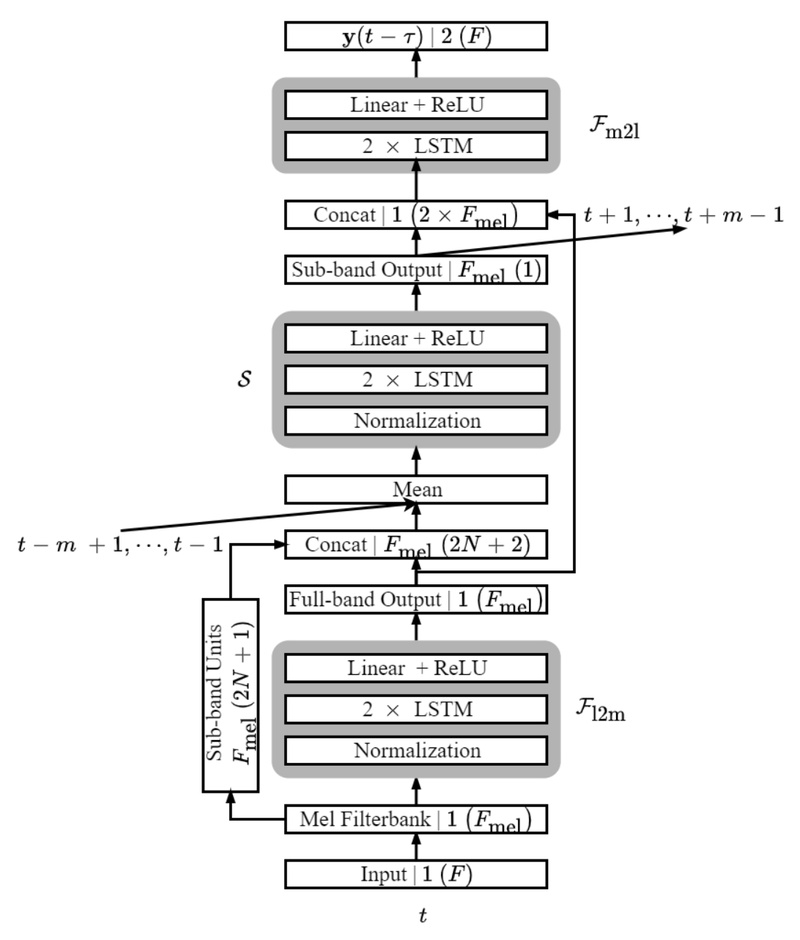
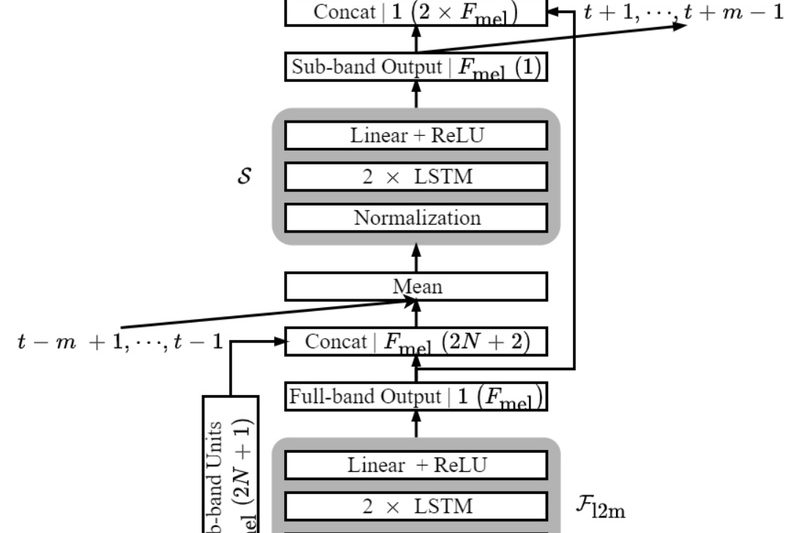
Fast FullSubNet addresses a critical challenge in modern audio applications: delivering high-quality, real-time speech enhancement on devices with strict constraints…
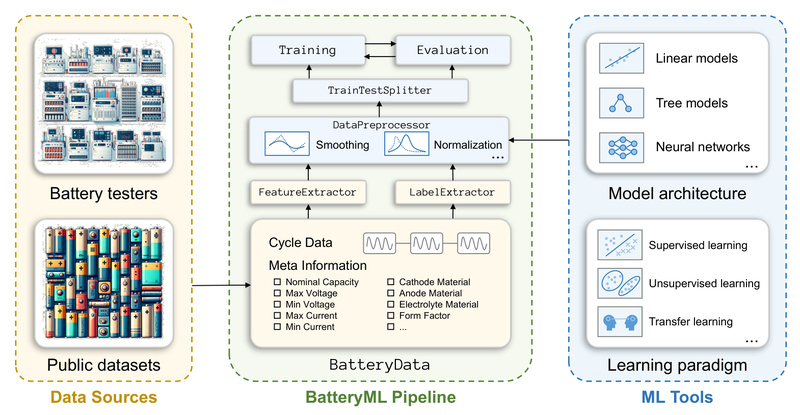
Battery degradation is a critical bottleneck in the deployment of electric vehicles (EVs), grid-scale energy storage, and portable electronics. Engineers…
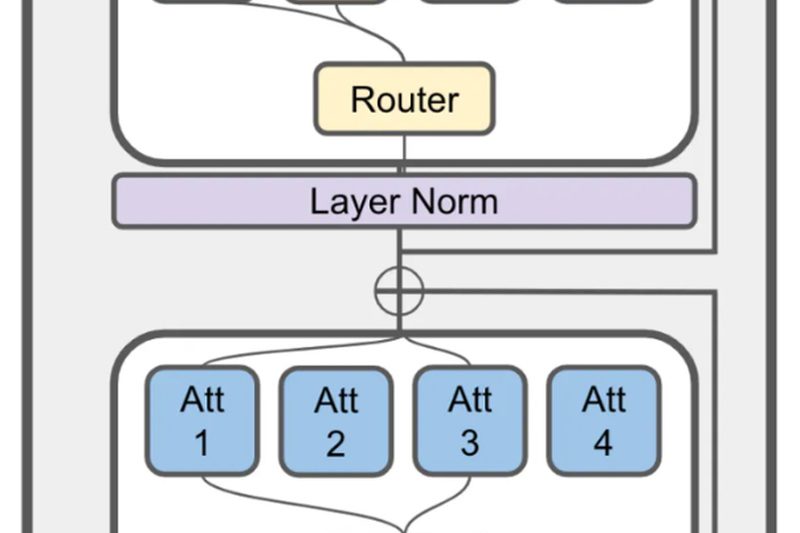
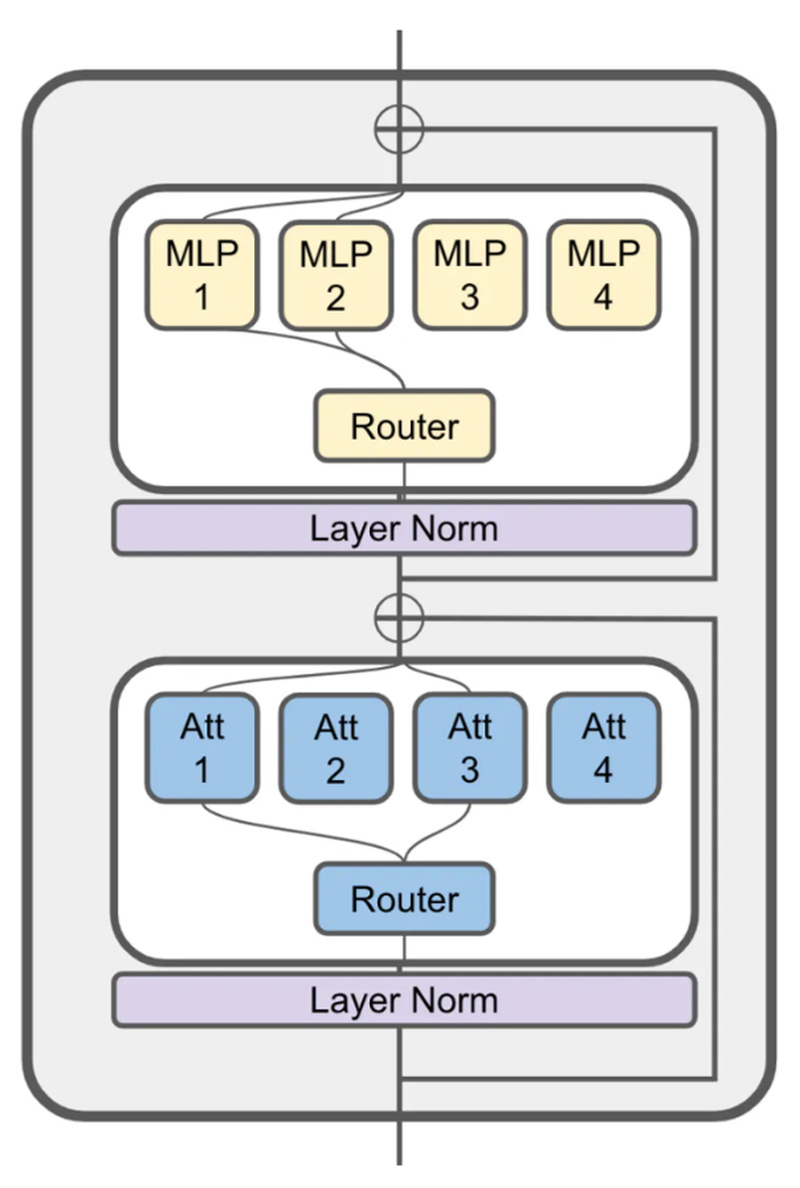
Building powerful language models used to be the exclusive domain of well-funded tech giants. But JetMoE is changing that narrative.…
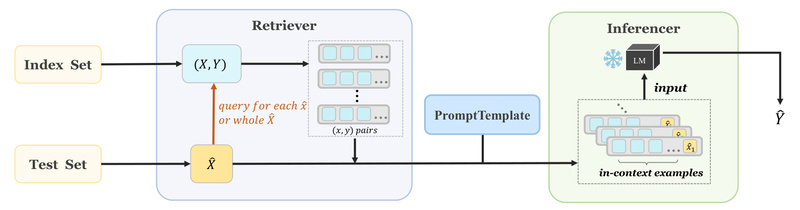
Evaluating large language models (LLMs) on new tasks traditionally requires fine-tuning—a process that’s time-consuming, resource-intensive, and often impractical when labeled…
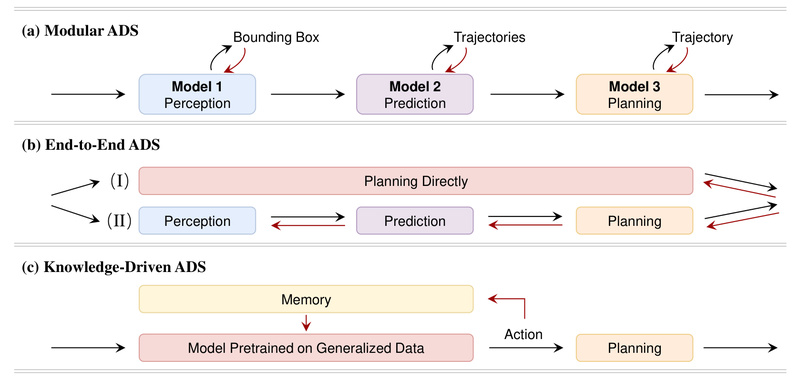
Validating autonomous driving systems (ADS) in realistic, complex urban environments is notoriously difficult. Real-world testing is expensive, risky, and often…

In the fast-evolving world of e-commerce and digital marketing, brands are under constant pressure to produce high-quality, engaging promotional videos—fast…
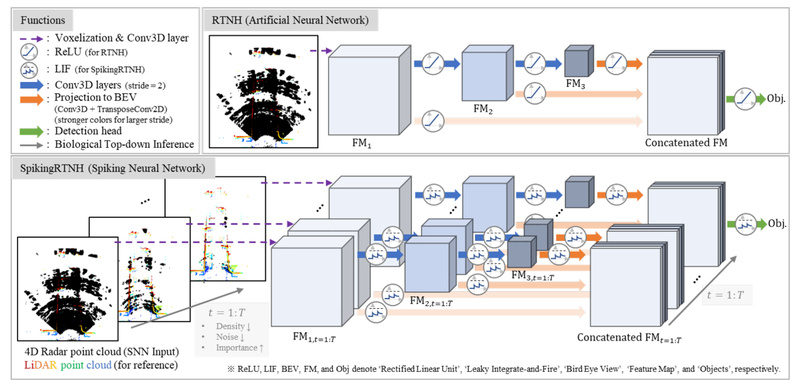
Autonomous driving systems demand robust, real-time perception under all environmental conditions—but traditional deep learning models struggle with the high computational…
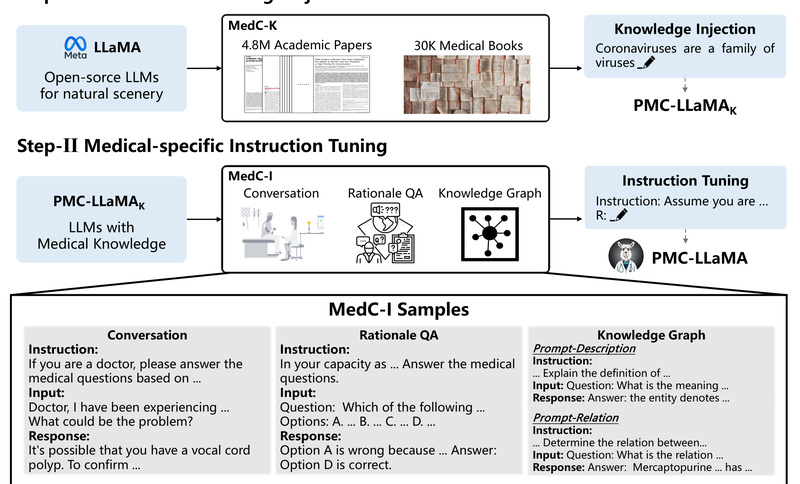
PMC-LLaMA is an open-source large language model explicitly engineered for the medical domain. Unlike general-purpose LLMs—such as LLaMA-2 or even…
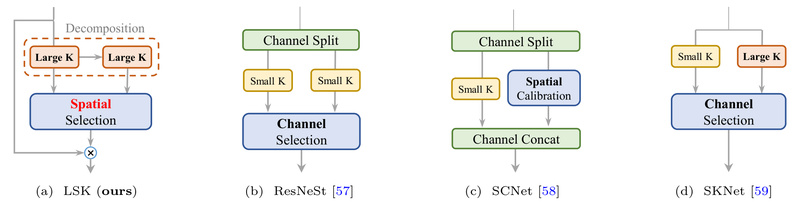
Remote sensing imagery—captured from satellites, drones, or aircraft—presents unique challenges for computer vision systems. Objects are often small, densely packed,…