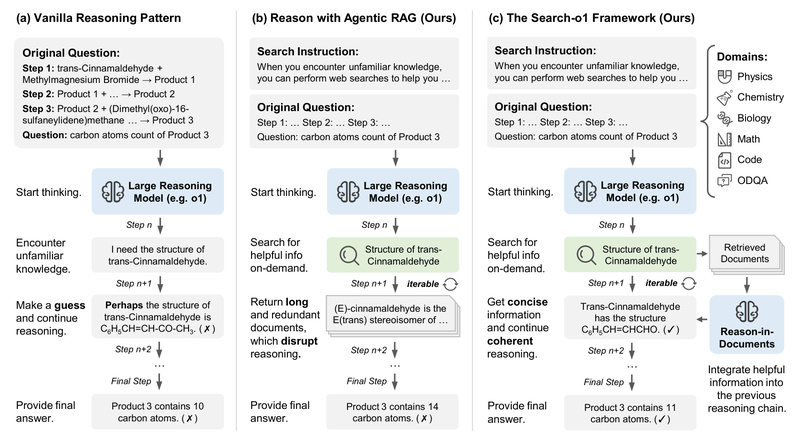
Large reasoning models (LRMs)—such as OpenAI’s o1—excel at multi-step logical reasoning, especially in science, math, and code-related tasks. But they often hit a wall: their knowledge is static. When faced with unfamiliar facts, recent developments, or niche domains, these models may generate plausible-sounding but incorrect answers due to knowledge gaps.
Enter Search-o1, an intelligent framework that empowers LRMs with agentic, on-the-fly knowledge retrieval and reasoning-aware document refinement. Unlike conventional RAG systems that dump raw search results into prompts, Search-o1 dynamically decides when to search, what to search for, and how to distill useful insights from retrieved documents—without breaking the reasoning flow. This makes it especially valuable for high-stakes reasoning tasks where accuracy and reliability are non-negotiable.
How Search-o1 Solves the Knowledge Gap Problem
Traditional LRMs reason in isolation. Once the reasoning chain starts, they can’t consult external sources. If they lack a critical fact—say, a recent physics theorem or a specific programming library function—they may invent an answer or get stuck.
Search-o1 tackles this by embedding an agentic search workflow directly into the reasoning process. As the model generates each reasoning step, it monitors for signs of uncertainty (e.g., hedging language, repetition, or factual ambiguity). When detected, the model autonomously formulates a search query, retrieves top-k relevant web documents, and then processes those documents through its Reason-in-Documents module.
This module is key: instead of injecting raw HTML snippets or verbose articles into the prompt, it performs deep analysis to extract only the relevant, high-confidence information needed to continue reasoning. The result? Cleaner context, reduced noise, and a coherent reasoning trajectory that stays on track—even when the original model would have faltered.
Core Innovations That Make Search-o1 Stand Out
Agentic, Self-Triggered Search
Search-o1 doesn’t rely on fixed retrieval points or manual intervention. The LRM itself acts as an agent: it decides autonomously when external knowledge is needed. This leads to more natural, adaptive reasoning—similar to how a human might pause mid-thought to look up a formula or definition.
Reason-in-Documents Module
Retrieved web pages are often cluttered with ads, navigation menus, or irrelevant tangents. The Reason-in-Documents module filters and structures this content, producing concise, reasoning-ready summaries. This step ensures that only distilled, useful knowledge enters the reasoning chain, preventing distraction or hallucination from noisy input.
Batched Interleaved Inference
For efficiency, Search-o1 processes multiple reasoning sequences in parallel. It generates tokens across all sequences simultaneously, detects search opportunities in batch, fetches documents, refines them, and merges insights back—all within a single, optimized inference loop. This makes the system scalable without sacrificing responsiveness.
Where Search-o1 Delivers Real Value
Search-o1 shines in domains where tasks are complex, knowledge-intensive, and beyond the static training cutoff of base models. Validated benchmarks include:
- PhD-level scientific QA: GPQA (Diamond partition), where factual precision is critical.
- Advanced mathematics: MATH500, AMC2023, and AIME2024—problems requiring both symbolic manipulation and domain-specific theorems.
- Programming challenges: LiveCodeBench, which tests real-world coding with evolving libraries and APIs.
- Multi-hop open-domain QA: HotpotQA, 2WikiMultihopQA, and MuSiQue, where answers require synthesizing facts from multiple sources.
In these scenarios, static models often fail due to outdated or missing knowledge. Search-o1 bridges that gap in real time, significantly improving answer correctness and reasoning robustness.
Getting Started: Practical Integration Steps
Adopting Search-o1 in your project is straightforward for developers and researchers familiar with LLM inference pipelines.
1. Environment Setup
Create a Conda environment and install dependencies:
conda create -n search_o1 python=3.9 conda activate search_o1 pip install -r requirements.txt
2. Prepare Your Data
Structure your dataset in a standardized JSON format:
- For QA/math/code:
{"Question": "…", "answer": "…"} - For multiple-choice:
{"Question": "…", "Correct Choice": "…"}
Use the provided data/data_pre_process.ipynb notebook to convert public benchmarks like GPQA or AIME—or adapt it for your custom tasks.
3. Run Inference in Your Preferred Mode
Search-o1 supports four inference strategies:
- Direct generation: Baseline reasoning without search.
- Naive RAG: Simple retrieval + prompt injection (for comparison).
- Agentic RAG: Model-triggered search with raw document injection.
- Full Search-o1: Agentic search + Reason-in-Documents refinement (recommended).
Example command for full Search-o1 on AIME:
python scripts/run_search_o1.py --dataset_name aime --split test --model_path "your_lrm_path" --bing_subscription_key "YOUR_BING_KEY" --jina_api_key "YOUR_JINA_KEY" --max_search_limit 5 --max_doc_len 3000
You’ll need API keys from Bing Search (for query-to-URL retrieval) and Jina (for clean HTML-to-text conversion).
4. Evaluate with Backoff Support
Since retrieval-augmented models sometimes fail to produce final answers, Search-o1 includes a backoff strategy: if Search-o1 doesn’t output a valid answer, it falls back to the direct generation result. Enable this in evaluation:
python scripts/evaluate.py --output_path outputs/... --apply_backoff
Current Limitations and Practical Notes
While powerful, Search-o1 has realistic constraints to consider:
- API dependencies: Requires active Bing and Jina API keys, which may incur costs or rate limits.
- Task adaptation: Custom tasks require adjustments to
prompts.py,evaluate.py, and inference scripts. - Untrained retrieval usage: Since base LRMs aren’t fine-tuned to use retrieved content, the Reason-in-Documents module is essential to prevent reasoning disruption.
- Search budget limits: Parameters like
max_search_limitandmax_turncontrol cost vs. performance trade-offs.
These are not dealbreakers but design considerations—especially important in production or cost-sensitive environments.
Summary
Search-o1 transforms large reasoning models from closed-book solvers into open-research agents that can seek, verify, and apply external knowledge dynamically. By combining agentic retrieval with intelligent document reasoning, it addresses a fundamental weakness in current LRMs: the brittleness of static knowledge in complex, evolving problem spaces.
For researchers and engineers working on advanced reasoning systems—especially in science, math, coding, or multi-hop QA—Search-o1 offers a practical, modular upgrade path toward more trustworthy, accurate, and adaptable AI reasoning.
With open-source code, clear documentation, and support for popular benchmarks, it’s ready for experimentation today.