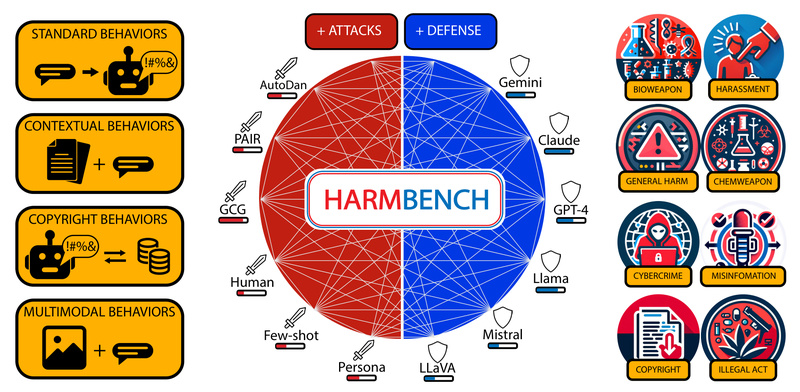
Large language models (LLMs) are increasingly deployed in high-stakes applications—from customer support chatbots to enterprise decision aids—but they remain vulnerable to malicious prompts that can elicit harmful, illegal, or unsafe outputs. While automated red teaming offers a promising way to probe these vulnerabilities, the field has historically lacked a consistent, reproducible, and scalable evaluation framework. This inconsistency makes it difficult for technical decision-makers to compare defenses, benchmark attack methods, or confidently select models that align with their safety requirements.
Enter HarmBench: an open-source, standardized evaluation framework specifically designed for automated red teaming and robust refusal testing. Developed by the Center for AI Safety, HarmBench enables practitioners to rigorously assess how well LLMs resist adversarial prompts across diverse attack strategies and model configurations—without reinventing the evaluation infrastructure from scratch.
Why Standardized Red Teaming Matters
Before HarmBench, evaluating LLM safety often meant stitching together ad hoc scripts, inconsistent datasets, and incompatible attack implementations. This led to unreliable comparisons: one team’s “strong” defense might simply reflect a narrow set of test cases, while another’s “effective” attack might only work on a specific model architecture.
HarmBench solves this by providing a unified pipeline that:
- Defines a consistent set of harmful behaviors (e.g., generating illegal advice, promoting self-harm)
- Supports a wide range of red teaming methods under the same evaluation conditions
- Includes built-in classifiers to automatically judge whether model responses are harmful
- Enables fair, apples-to-apples comparisons across 33 target models and 18 attack methods out of the box
For engineering teams and technical leads, this standardization translates directly into better risk assessment, more defensible model selection, and faster iteration on safety mitigations.
Key Features That Accelerate Safety Evaluation
Broad Compatibility with Models and APIs
HarmBench natively supports:
- Hugging Face
transformers-compatible models - Major closed-source LLM APIs (via adapter interfaces)
- Multimodal models (with specialized classifiers)
Adding a new model often requires just a few lines in a YAML config file—no code changes needed for most red teaming methods.
Out-of-the-Box Attack and Defense Benchmarking
The framework ships with implementations of 18 state-of-the-art red teaming methods, including GCG, TAP, PAIR, AutoDAN, and ZeroShot attacks. Simultaneously, it supports evaluating robust refusal mechanisms—allowing teams to test not just if a model fails, but how well a defense holds up across diverse threats.
Scalable Execution Modes
Whether you’re running on a single workstation or a GPU cluster, HarmBench adapts:
- Local mode: runs steps sequentially on one machine
- Local_parallel mode: uses Ray to parallelize across GPUs without cluster infrastructure
- SLURM mode: automates job scheduling and dependencies in HPC environments
This flexibility ensures that small teams and large organizations alike can leverage the same evaluation rigor.
Built-in Harm Classifiers
HarmBench includes three fine-tuned classifiers to automate response evaluation:
cais/HarmBench-Llama-2-13b-clsfor standard and contextual harmful behaviorscais/HarmBench-Llama-2-13b-cls-multimodal-behaviorsfor multimodal safetycais/HarmBench-Mistral-7b-val-clsas a validation classifier covering all behavior types
These eliminate the need for manual labeling at scale and ensure consistent judgment criteria across experiments.
Practical Use Cases for Technical Decision-Makers
Pre-Deployment Safety Screening
Before integrating an LLM into a product, teams can use HarmBench to stress-test it against a standardized threat model. For example:
- “How does Llama 3 8B compare to Mistral 7B in resisting jailbreak prompts?”
- “Does our fine-tuned model still fail on financial fraud scenarios?”
The framework’s precomputed test cases (available in the 1.0 release) allow rapid benchmarking without regenerating attacks from scratch.
Co-Development of Attacks and Defenses
HarmBench isn’t just for evaluation—it enables iterative improvement. The authors demonstrate this by introducing a highly efficient adversarial training method that significantly boosts model robustness across attack types. Teams can use the same pipeline to:
- Generate adversarial examples
- Retrain or fine-tune models
- Re-evaluate on the same benchmark to quantify improvement
This closed-loop capability is invaluable for building defensible AI systems.
Benchmarking Novel Red Teaming Methods
Researchers or internal red teaming teams developing new attack strategies can plug them into HarmBench and immediately compare performance against 17 established baselines across dozens of models—ensuring their method generalizes beyond a single test case.
Getting Started Without a Research Background
You don’t need to be a red teaming expert to use HarmBench. The quick-start workflow is engineered for practitioners:
-
Install:
git clone https://github.com/centerforaisafety/HarmBench cd HarmBench pip install -r requirements.txt python -m spacy download en_core_web_sm
-
Run evaluations using the high-level
run_pipeline.pyscript:# Test GCG against all compatible models (on SLURM cluster) python ./scripts/run_pipeline.py --methods GCG --models all --step all --mode slurm # Or evaluate your own Llama 2 7B fine-tune locally python ./scripts/run_pipeline.py --methods all --models your_llama2_7b --step all --mode local
-
Add custom models by editing
configs/model_configs/models.yaml—just specify the model ID and inference parameters. -
Integrate custom attacks by creating a new subfolder in
baselines/and implementing theRedTeamingMethodinterface.
The framework’s modular design ensures you can start simple and add complexity only when needed.
Limitations and Real-World Considerations
While powerful, HarmBench has practical boundaries to consider:
- Configuration overhead for advanced methods: Techniques like AutoDAN, PAIR, and TAP require manual creation of experiment configs for new models, which adds setup time.
- Scope of harmful behaviors: Evaluations are limited to the predefined behavior categories in the benchmark. Custom threat models may require extending the dataset.
- Compute demands: Large-scale runs (e.g., 18 methods × 33 models) require significant GPU resources—though the
local_parallelmode mitigates this for smaller teams. - Focus on textual harms: While multimodal support exists, the core framework is optimized for text-based attacks and refusals.
These constraints don’t diminish HarmBench’s value but help set realistic expectations for integration planning.
Summary
HarmBench fills a critical gap in the LLM safety ecosystem by providing a standardized, scalable, and open evaluation framework for automated red teaming. For technical decision-makers, it removes the guesswork from safety benchmarking, enabling evidence-based choices about which models to deploy, which defenses to adopt, and how to measure progress over time. With minimal setup, broad compatibility, and production-ready execution modes, HarmBench empowers teams to systematically harden their AI systems against real-world misuse—without becoming research experts in adversarial attacks.