Imagine building an AI system that understands not just images and text—but also video, audio, infrared (thermal), and depth data—all aligned to the same semantic meaning expressed in natural language. Until recently, such multimodal integration required complex custom pipelines, massive paired datasets across every modality combination, or intermediate representations that limited scalability.
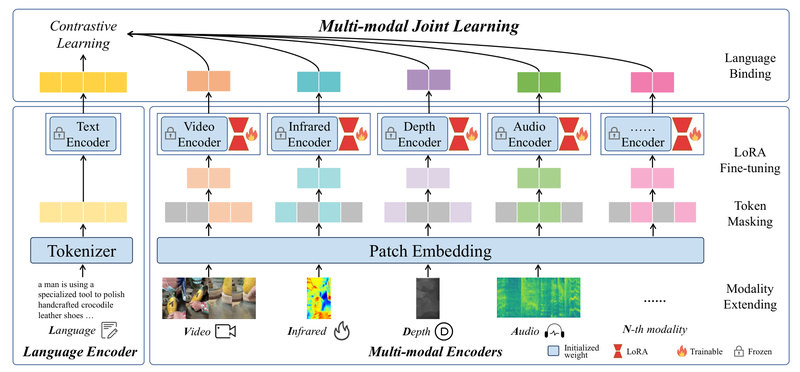
Enter LanguageBind, a breakthrough multimodal foundation model from PKU-YuanGroup that rethinks multimodal alignment by using language as the universal binding modality. Rather than forcing every sensor modality to align directly with vision or with each other, LanguageBind anchors all modalities—including video, audio, depth, thermal, and images—to a shared language space. This elegant design enables seamless extension to new modalities without retraining the entire system, while delivering state-of-the-art performance across 15+ benchmarks.
For project leads, engineering teams, and researchers evaluating multimodal AI solutions, LanguageBind offers a rare combination: strong zero-shot generalization, modular architecture, and production-ready APIs—all backed by a large-scale, language-centered dataset called VIDAL-10M.
Why Language-Centric Alignment Changes the Game
Traditional vision-language models like CLIP excel at aligning images and text but struggle when additional modalities—such as audio or thermal imaging—are introduced. Most approaches either:
- Require explicit pairwise training data (e.g., video-audio pairs), which is expensive and scarce, or
- Rely on intermediate fusion modules that become unwieldy as modalities increase.
LanguageBind flips this paradigm. It freezes a pre-trained language encoder (borrowed from a strong video-language model) and trains modality-specific encoders (for video, audio, etc.) to map into the same embedding space as text. This means every non-language modality learns to “speak the language” of semantics—not through direct cross-modal supervision, but through contrastive alignment with descriptive text.
The result? A scalable framework where adding a new modality (say, LiDAR or EEG) only requires training a new encoder while reusing the frozen language backbone. No need to retrain the entire system or collect N×N paired data across all combinations.
Real-World Strengths: Performance, Flexibility, and Emergent Capabilities
1. Strong Zero-Shot and Fine-Tuned Performance
LanguageBind achieves state-of-the-art results on four video-language benchmarks (MSR-VTT, DiDeMo, ActivityNet, MSVD) and delivers competitive zero-shot accuracy across audio, depth, and thermal tasks. Fully fine-tuned variants (e.g., LanguageBind_Video_FT) consistently outperform LoRA-tuned versions, offering a clear upgrade path for performance-critical applications.
2. “Emergency Zero-Shot” Cross-Modal Retrieval
One of LanguageBind’s most surprising features is its ability to perform cross-modal matching without any direct training pairs. For example, given embeddings from video and audio encoders—both aligned to language—the system can compute video-audio similarity as if they were trained together. In practice, this enables tasks like retrieving relevant audio clips using video queries, even if the model never saw video-audio pairs during training.
This emergent capability stems directly from the shared language-aligned space: if both modalities understand the phrase “a dog barking,” they implicitly understand each other.
3. Plug-and-Play API for Rapid Prototyping
LanguageBind ships with a unified inference API that handles preprocessing, tokenization, and embedding generation across all supported modalities with just a few lines of code. Whether you’re processing thermal images, depth maps, or short videos, the interface remains consistent—dramatically reducing integration friction for engineers.
For quick validation, the project includes a local Gradio demo (python gradio_app.py) and a hosted Hugging Face Space where users can test modality-to-text similarity interactively.
Practical Use Cases Across Industries
LanguageBind isn’t just a research artifact—it solves tangible problems in real-world systems:
- Industrial IoT & Robotics: Align thermal or depth sensor data with maintenance logs or operational instructions (e.g., “overheating motor in bay 3”) to enable semantic search over equipment telemetry.
- Accessibility Tools: Build systems that link ambient audio cues (“fire alarm”) to visual or thermal context for users with sensory impairments.
- Content Platforms: Enable users to search short videos using spoken descriptions or retrieve related audio clips based on visual content—without explicit metadata.
- AR/VR & Spatial Computing: Fuse multimodal inputs (video, depth, audio) into a single semantic understanding layer grounded in natural language, simplifying scene interpretation.
Because LanguageBind treats language as the coordination hub, it’s especially valuable in scenarios where human-readable context—not just raw sensor fusion—is critical.
Getting Started: No PhD Required
You don’t need to train from scratch to benefit from LanguageBind. Here’s how to begin:
- Install via PyPI-style setup (requires Python ≥3.8, PyTorch ≥1.13.1, CUDA ≥11.6).
- Load pre-trained models directly from Hugging Face (e.g.,
LanguageBind/LanguageBind_Audio_FT). - Run inference using the unified
LanguageBindclass that accepts video, audio, depth, thermal, image, and text inputs simultaneously. - Experiment with the provided sample assets (
assets/) to see zero-shot alignment in action.
For custom training, the VIDAL-10M dataset—containing 10 million aligned samples across video, infrared, depth, audio, and descriptive text—is available to the research community. The dataset’s short-video format ensures complete semantic context (unlike clipped segments from movies), and language descriptions are enhanced with metadata, spatial, and temporal cues—often refined via LLMs like ChatGPT—to maximize semantic richness.
Critically, you can add new modalities incrementally: train a depth encoder while reusing the frozen language model, then later add thermal without disrupting existing capabilities.
Important Limitations to Consider
While powerful, LanguageBind has realistic boundaries:
- The image encoder is not fine-tuned; it inherits weights from OpenCLIP and may lag behind modality-specific encoders in alignment quality.
- Depth and thermal models currently only support LoRA tuning, not full fine-tuning—though performance remains strong in zero-shot settings.
- Performance depends on high-quality textual descriptions; noisy or vague language reduces cross-modal alignment fidelity.
- Hardware requirements (CUDA 11.6+, modern GPUs) may pose barriers for edge deployment without quantization or distillation.
Additionally, while VIDAL-10M is large and diverse, domain-specific applications (e.g., medical imaging or satellite data) may require fine-tuning on proprietary datasets.
Summary
LanguageBind redefines multimodal AI by making language the central alignment mechanism—enabling scalable, flexible, and high-performing integration of heterogeneous data streams. Its combination of strong benchmarks, emergent zero-shot capabilities, and developer-friendly APIs makes it a compelling choice for teams building next-generation multimodal systems in robotics, content understanding, industrial automation, and beyond. If your project involves coordinating multiple sensor types around human-meaningful semantics, LanguageBind offers a principled, practical path forward—without the usual architectural bloat or data hunger.