For years, unconditional image generation—creating realistic images without relying on human-provided class labels—has lagged significantly behind its class-conditional counterpart in…
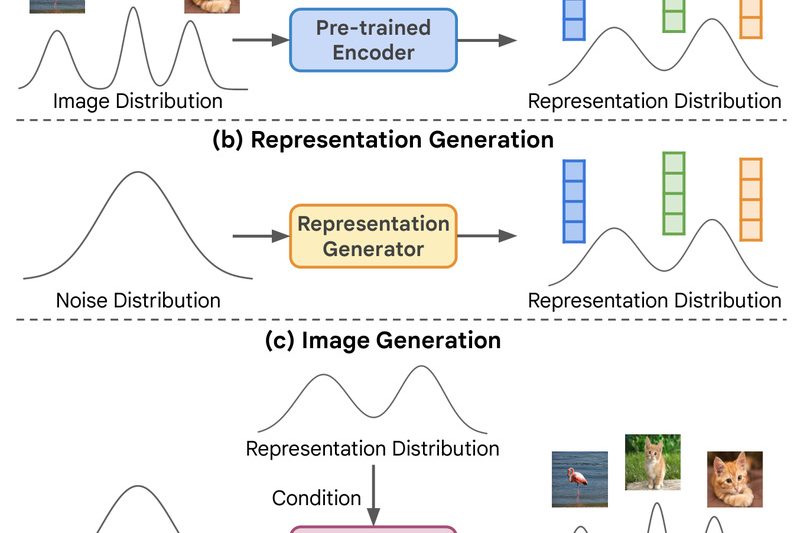
For years, unconditional image generation—creating realistic images without relying on human-provided class labels—has lagged significantly behind its class-conditional counterpart in…
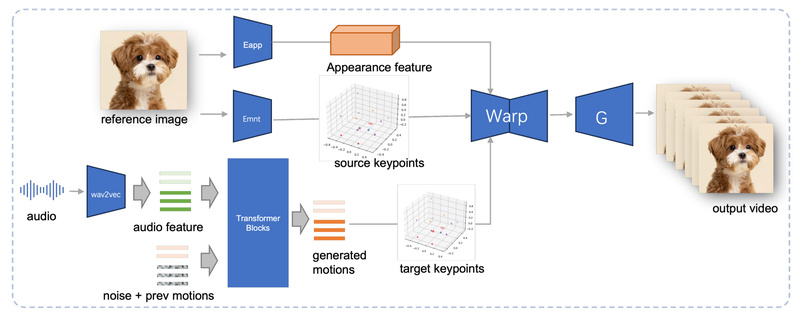
Audio-driven facial animation has long been a challenging yet highly valuable capability—from building expressive virtual agents to creating personalized pet…
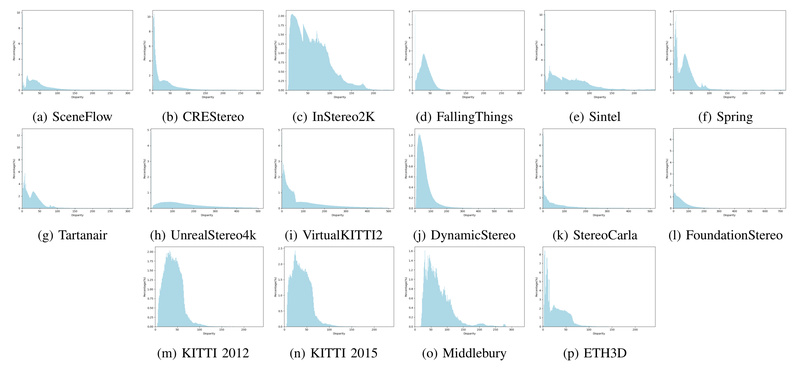
Stereo matching—the task of finding corresponding pixels between left and right images to infer depth—is foundational to 3D vision systems…

Solving complex reasoning problems is a persistent challenge for Large Language Models (LLMs). While techniques like Chain-of-Thought (CoT) prompting have…
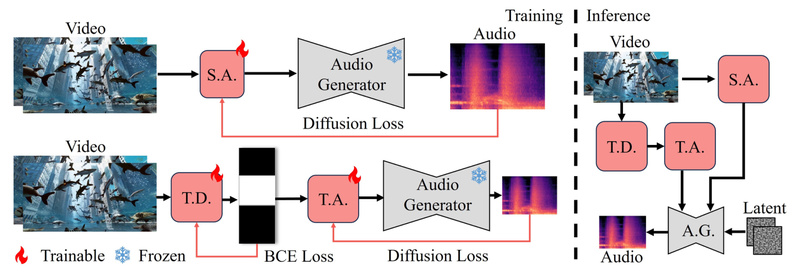
Silent videos—whether from AI-generated content, archival footage, gameplay recordings, or unfinished film prototypes—often lack the immersive quality that sound brings.…
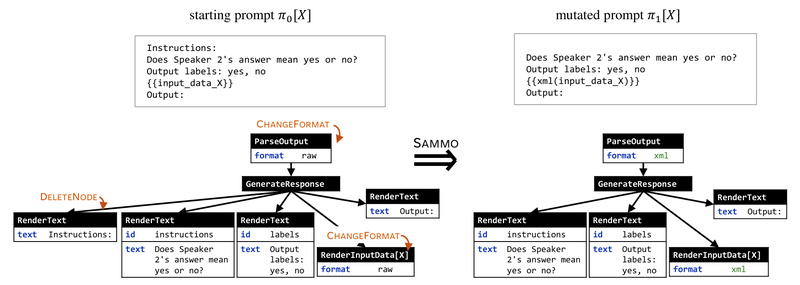
Modern LLM applications increasingly rely on complex, structured prompts—especially in scenarios like Retrieval-Augmented Generation (RAG), instruction-based tasks, and data labeling…
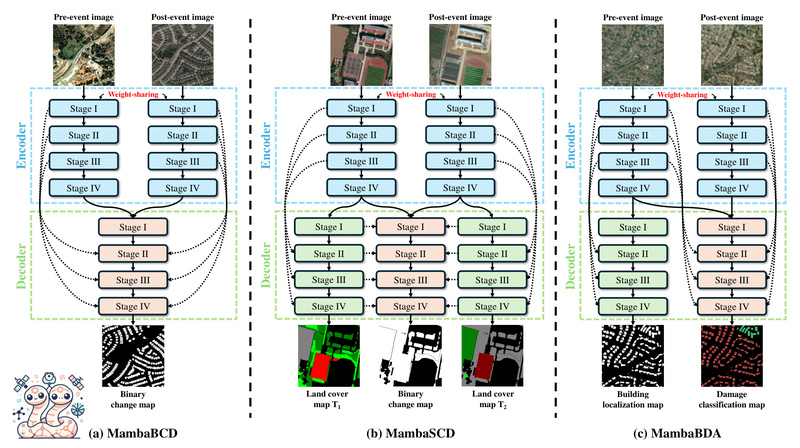
Change detection in remote sensing—identifying what has changed between two satellite or aerial images taken at different times—is a critical…
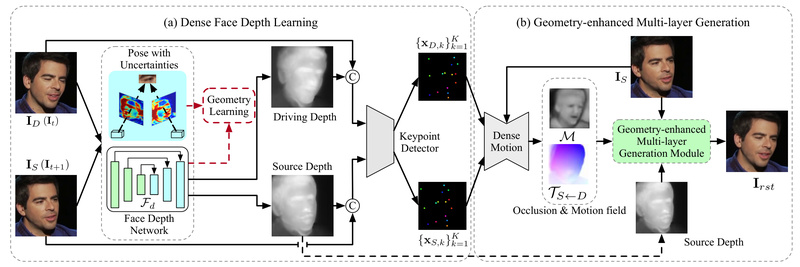
Creating lifelike talking head videos—where a static portrait speaks and moves in sync with an audio or driving video—has long…

Large Multimodal Models (LMMs) like GPT-4V and Gemini promise powerful vision-language understanding—but how well do they actually read text in…

Imagine building a system that can understand 3D objects as intuitively as humans do—recognizing a chair from its point cloud,…