Traditional multi-agent systems powered by large language models (LLMs) often follow rigid, sequential workflows—like a single assembly line where each…
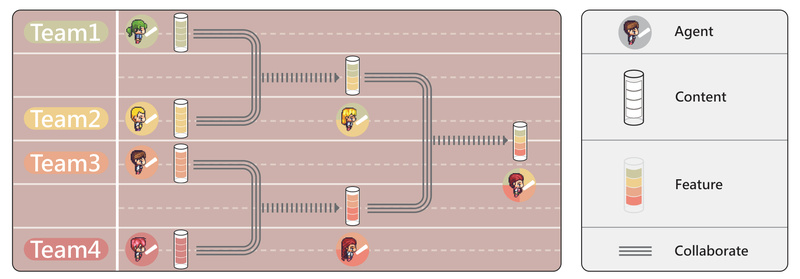
Traditional multi-agent systems powered by large language models (LLMs) often follow rigid, sequential workflows—like a single assembly line where each…
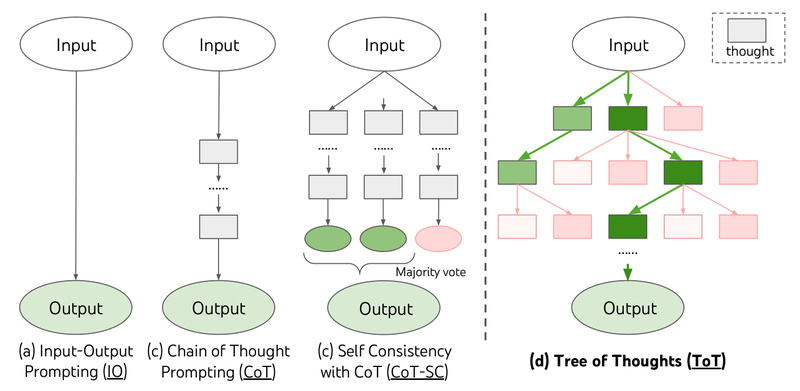
Large language models (LLMs) have transformed how we approach tasks ranging from coding assistance to content generation. Yet, their standard…

Text-to-image generation has made remarkable strides, yet even state-of-the-art models like DALL·E 3 or Stable Diffusion XL (SDXL) often stumble…
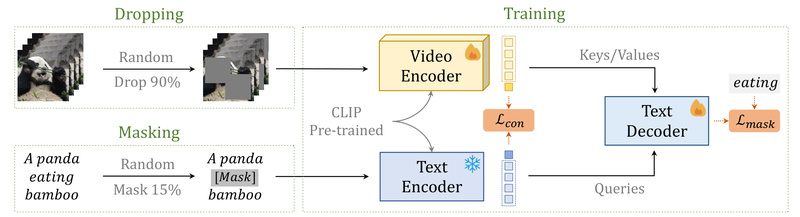
Building capable video-language AI systems has long been a resource-intensive endeavor—requiring vast video datasets, weeks of training on dozens of…
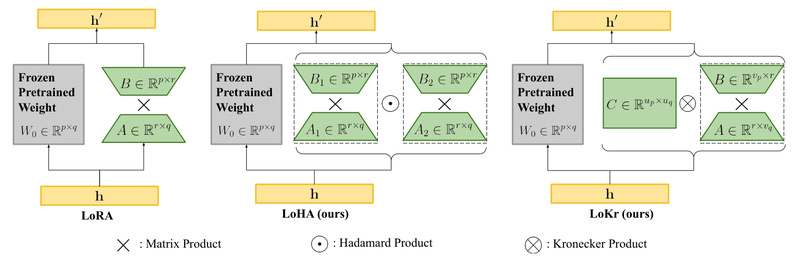
If you’re working with text-to-image models like Stable Diffusion, you’ve likely faced the trade-off between customization and efficiency. Full fine-tuning…
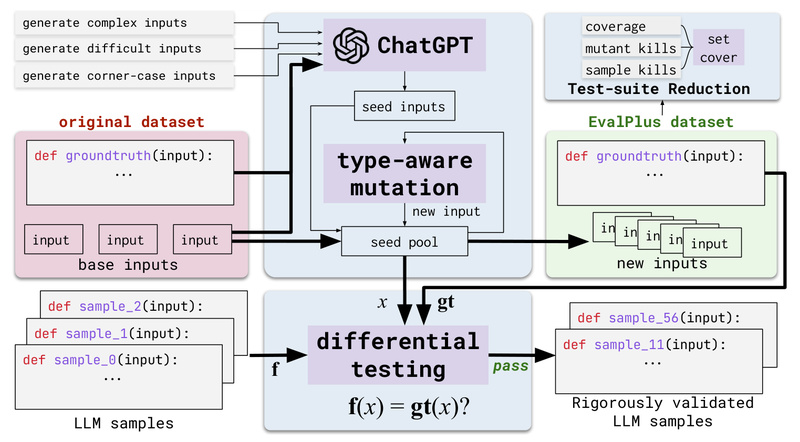
When large language models (LLMs) generate code, how do you know it’s actually correct? Traditional code evaluation benchmarks like HumanEval…
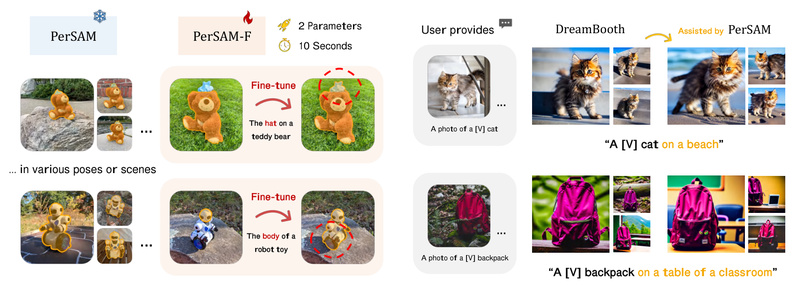
Imagine you have a photo album filled with images of your dog—but you want to automatically isolate your pet in…
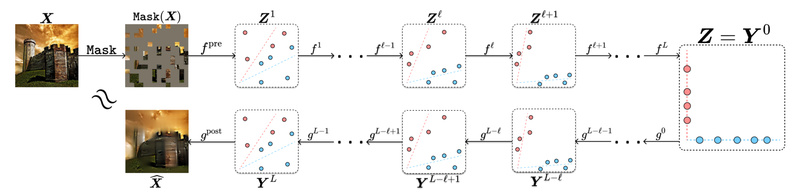
In an era where deep learning models grow ever larger and more opaque, the demand for interpretable, efficient, and theoretically…
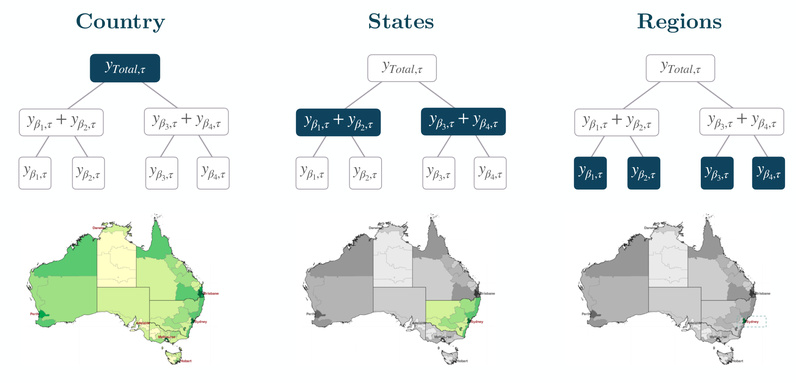
Time series forecasting remains a core challenge across industries—from retail and energy to finance and logistics. While deep learning has…
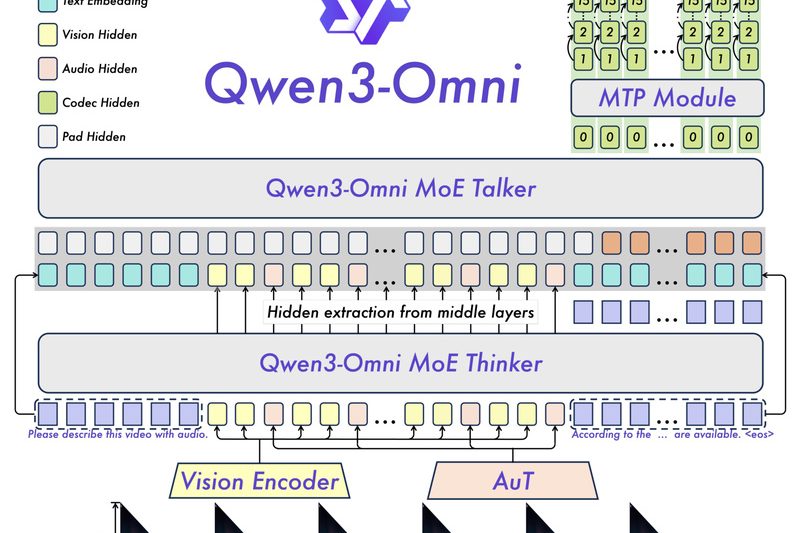
Imagine a single AI model that natively understands and generates responses across text, images, audio, and video—all in real time,…