Training large-scale deep neural networks (DNNs) efficiently is a persistent challenge—especially when your infrastructure includes a mix of hardware like…
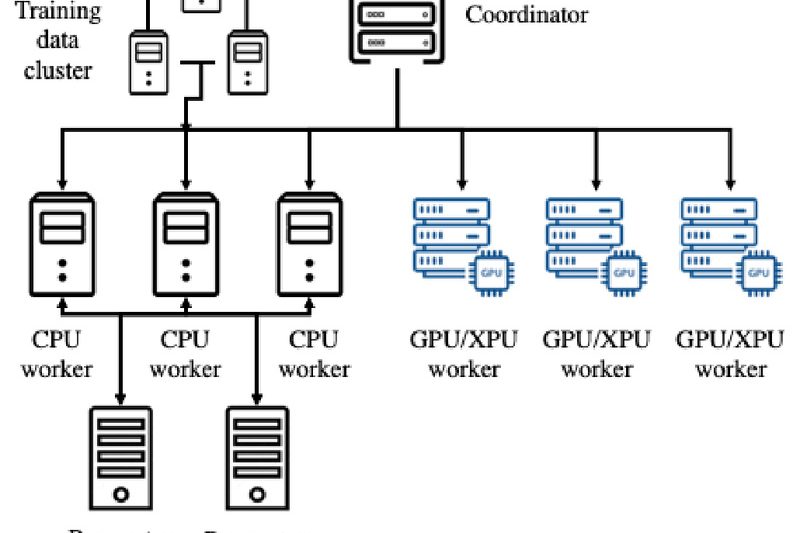
Training large-scale deep neural networks (DNNs) efficiently is a persistent challenge—especially when your infrastructure includes a mix of hardware like…

If you’re evaluating vision-language models for a project that involves both images and videos, you’ve probably faced a frustrating trade-off:…
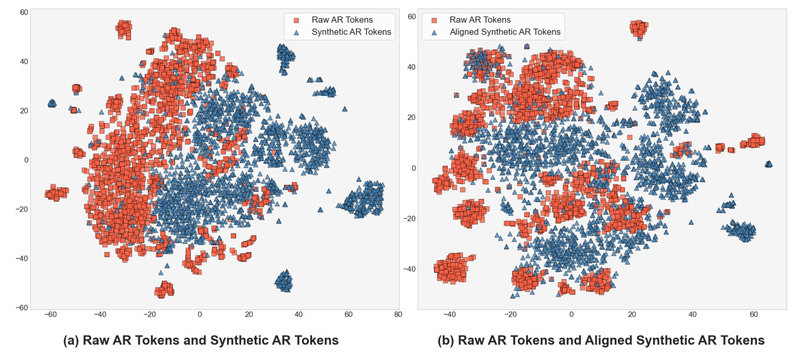
Recent advances in speech language models (SLMs) have made it possible to generate highly realistic speech—often indistinguishable from human voices…
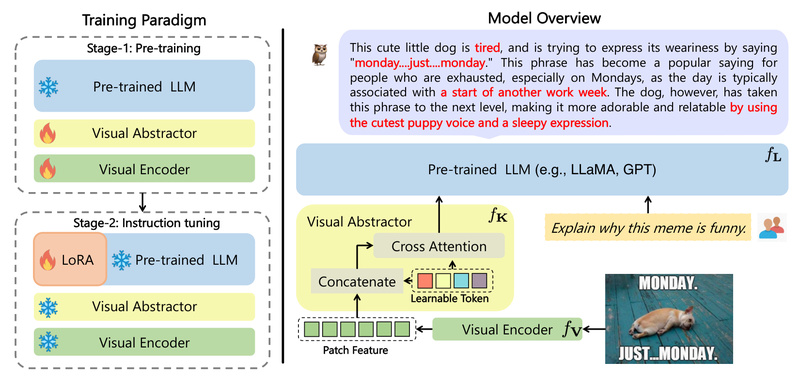
In today’s AI-driven product landscape, the ability to understand both images and text isn’t just a research novelty—it’s a practical…
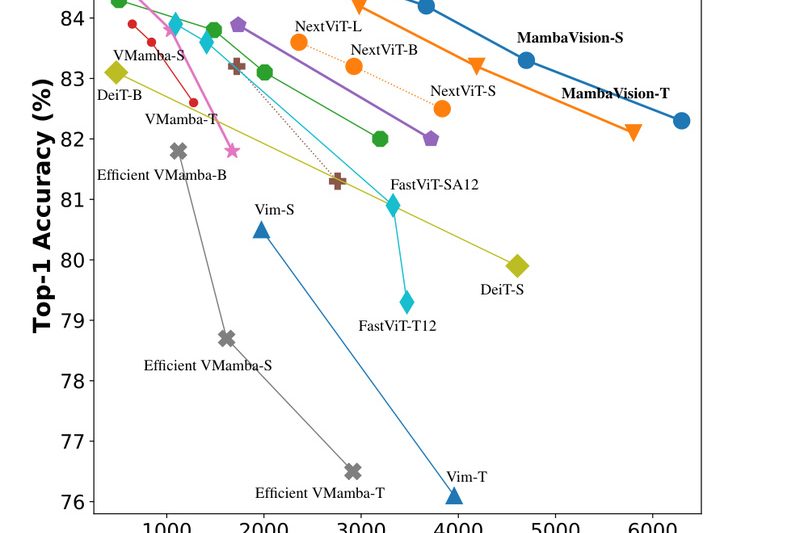
If you’re building computer vision systems that demand both high accuracy and real-world efficiency—without getting bogged down in architectural complexity—MambaVision…
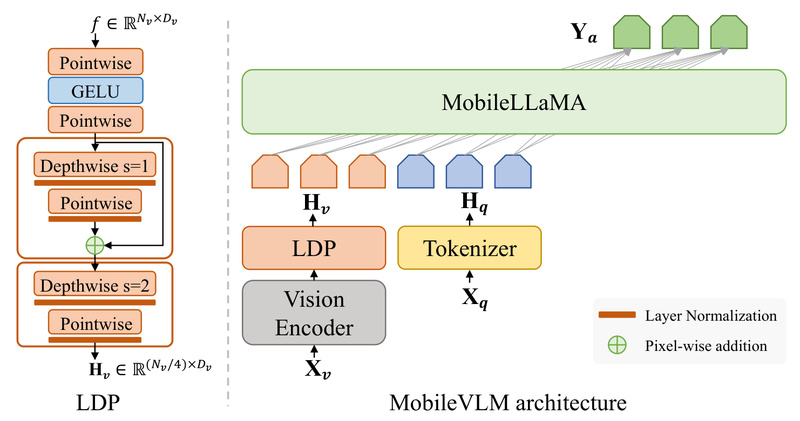
MobileVLM is a purpose-built vision-language model (VLM) engineered from the ground up for on-device deployment on smartphones and edge hardware.…

In today’s fast-evolving AI landscape, most generative systems are built for a single task—whether that’s turning text into images, editing…
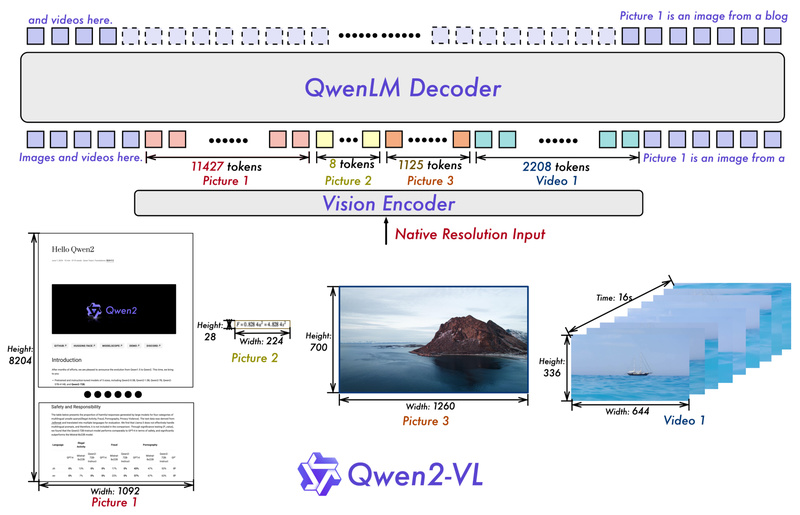
Vision-language models (VLMs) are increasingly essential for tasks that require joint understanding of images, videos, and text—ranging from document parsing…
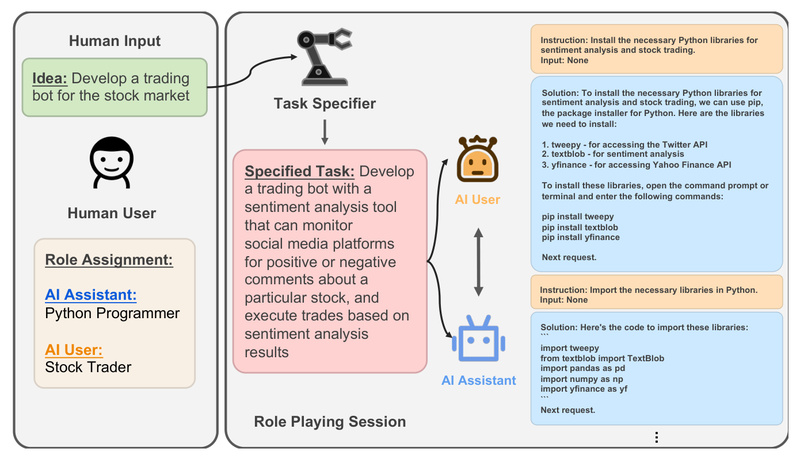
In today’s AI landscape, large language models (LLMs) excel at solving complex tasks—but only when carefully guided by humans. This…
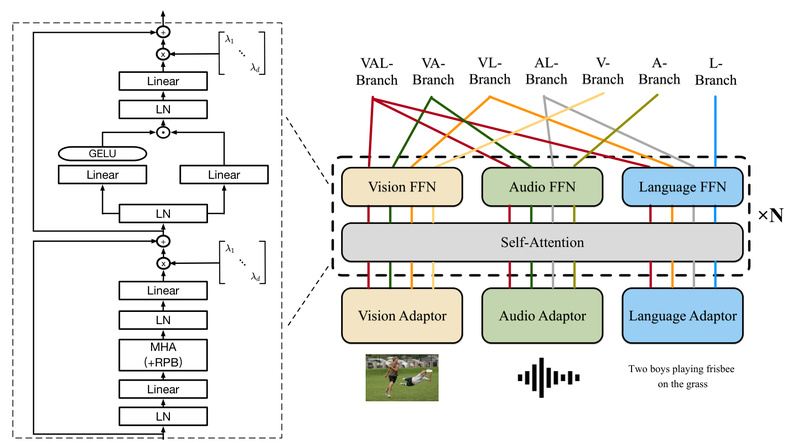
In today’s AI landscape, most multimodal systems are built by stitching together specialized models—separate vision encoders, audio processors, and language…