OOTDiffusion represents a significant leap forward in image-based virtual try-on (VTON) technology. Built on the foundation of pretrained latent diffusion…

OOTDiffusion represents a significant leap forward in image-based virtual try-on (VTON) technology. Built on the foundation of pretrained latent diffusion…
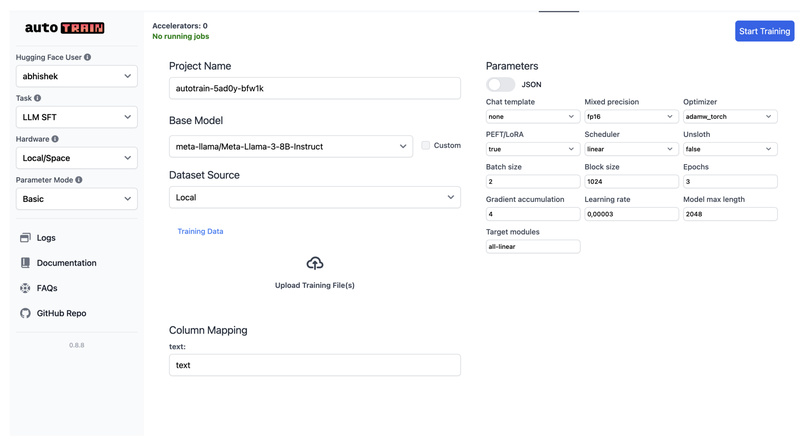
In today’s fast-moving AI landscape, fine-tuning state-of-the-art models on custom data is no longer a luxury—it’s a necessity for building…

Imagine asking a computer vision system to “segment the object that makes the woman stand higher” or “show me the…
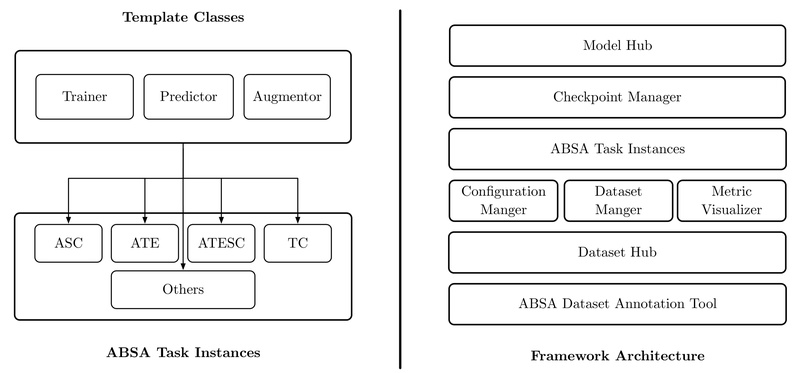
Aspect-Based Sentiment Analysis (ABSA) has become essential for extracting fine-grained opinions from text—such as determining whether a customer loves a…
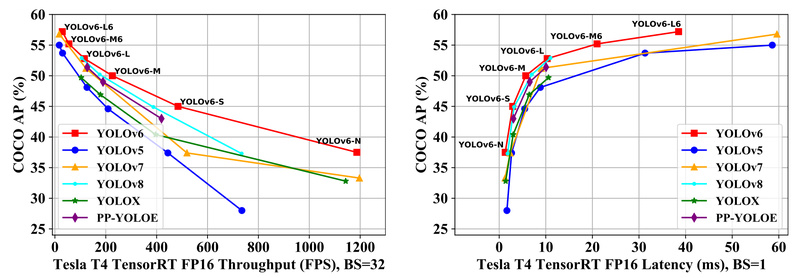
YOLOv6 is a high-performance, single-stage object detection framework developed by Meituan with a strong emphasis on real-world industrial applications. Unlike…
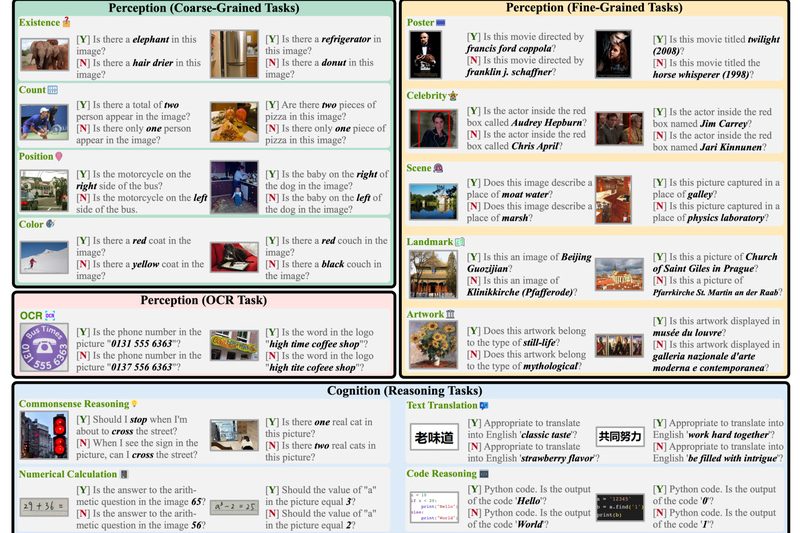
Multimodal Large Language Models (MLLMs) have captured the imagination of researchers and developers alike—promising capabilities like generating poetry from images,…
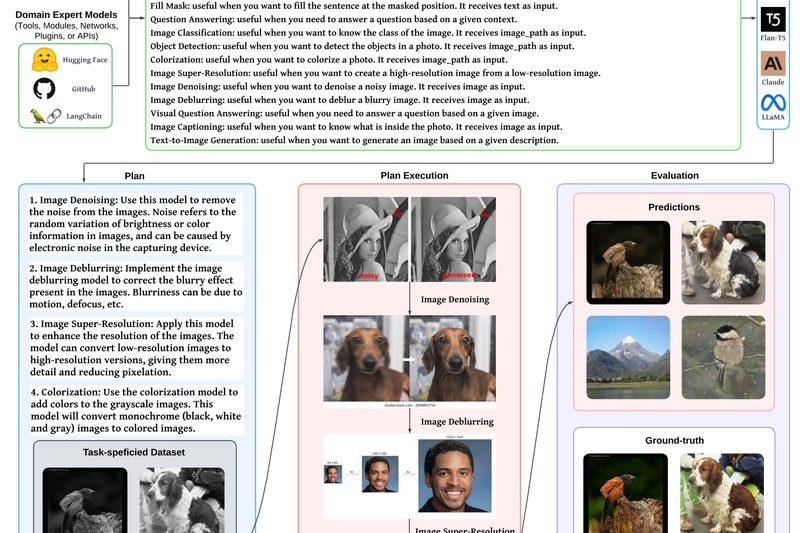
In today’s AI landscape, building systems that handle real-world complexity often means stitching together language models, specialized tools, APIs, and…
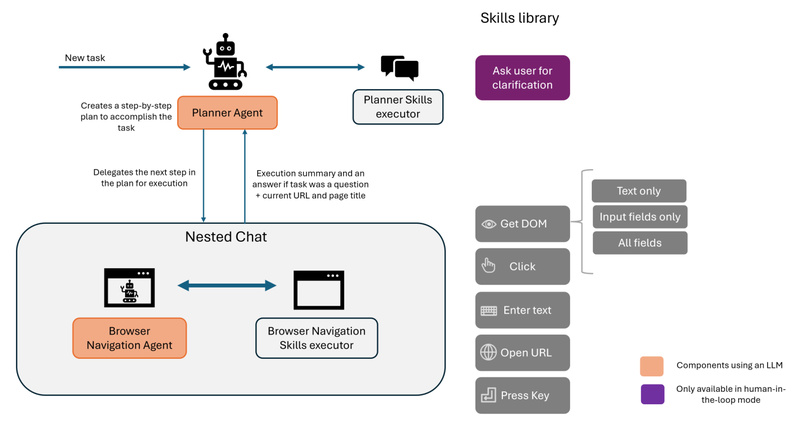
In today’s fast-paced digital landscape, automating browser-based workflows—from filling forms to comparing products—has become essential for both individuals and enterprises.…
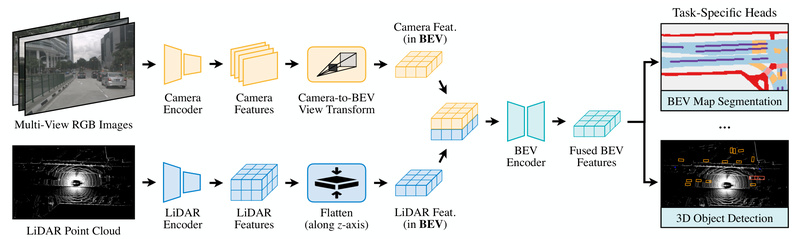
Building reliable perception systems for autonomous driving demands more than just collecting data from cameras and LiDARs—it requires intelligently fusing…
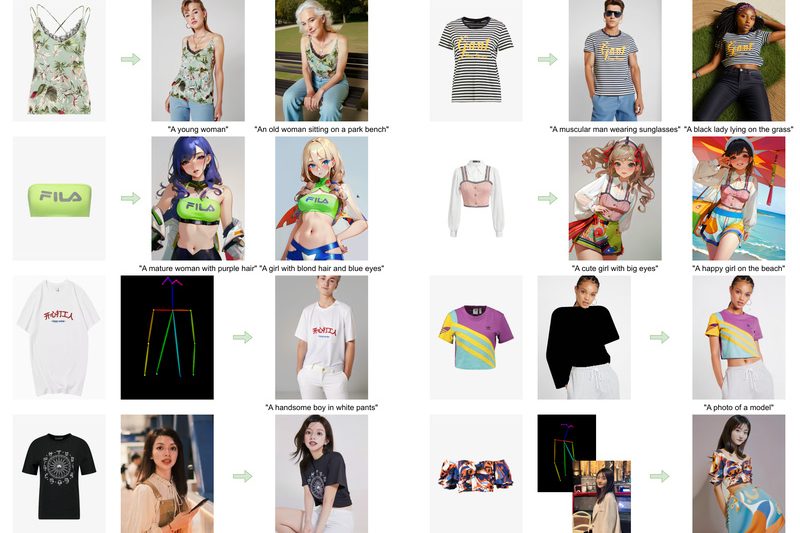
Magic Clothing is a cutting-edge solution for a long-standing challenge in AI-powered visual content creation: how to generate realistic human…