InstantStyle is a breakthrough framework that enables high-fidelity, style-consistent image generation without requiring any model retraining or per-image tuning. Built…

InstantStyle is a breakthrough framework that enables high-fidelity, style-consistent image generation without requiring any model retraining or per-image tuning. Built…
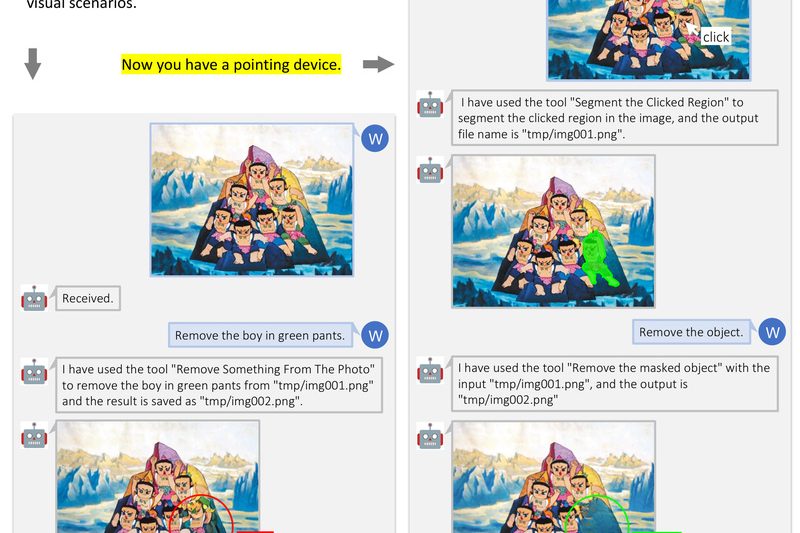
In today’s AI landscape, large language models (LLMs) like ChatGPT have transformed how we interact with software—through natural language. But…
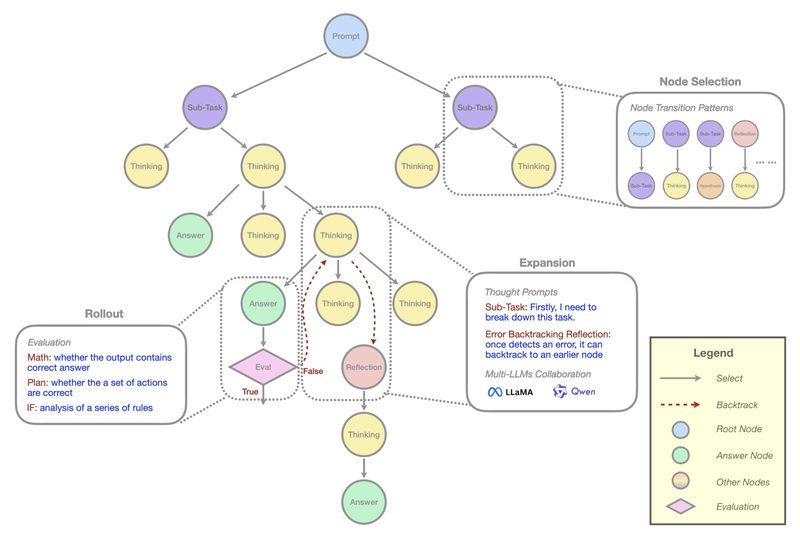
As large reasoning models (LRMs) like OpenAI’s o1 demonstrate unprecedented capabilities in math, code, and planning, a critical gap remains:…
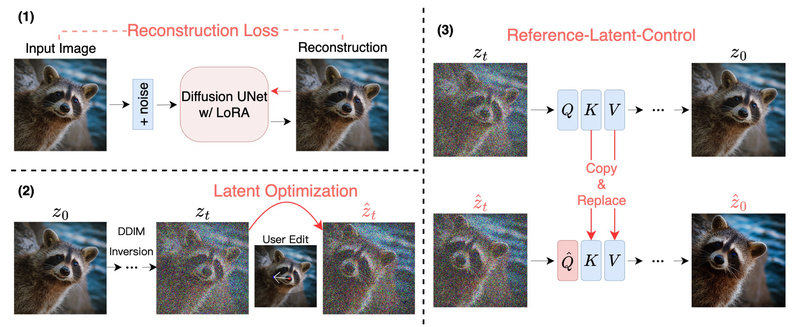
DragDiffusion is an open-source framework that brings pixel-precise, point-based image manipulation to both real-world photographs and AI-generated images—without requiring users…

Modern image generation is powerful—but fragmented. Depending on your goal—generating from text, editing existing images, preserving a person’s identity, or…
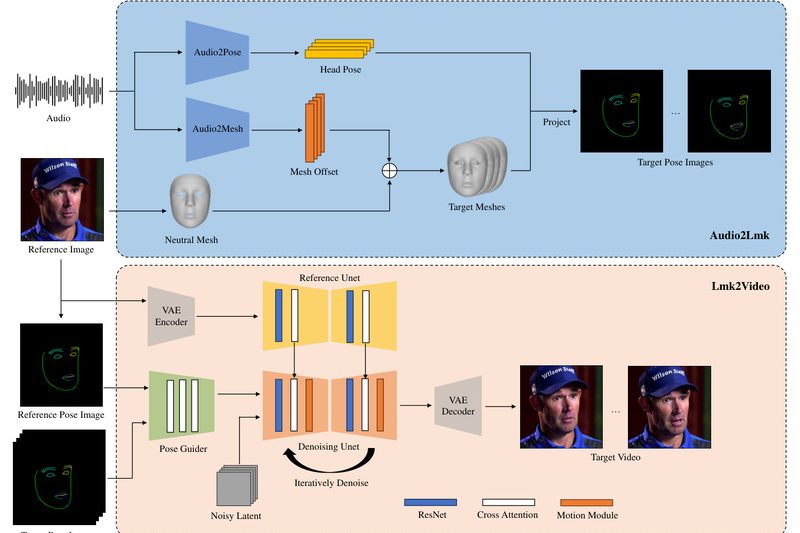
Creating lifelike, animated human faces used to require complex pipelines—motion capture rigs, professional voice actors, or hours of post-production. But…

Creating photorealistic 3D models of real-world objects typically demands dozens—or even hundreds—of input images captured from carefully calibrated viewpoints. This…
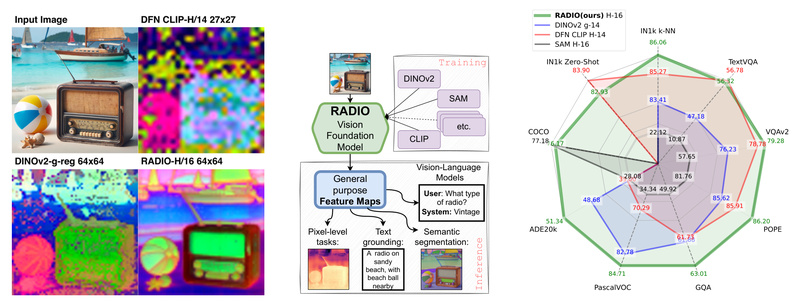
In modern computer vision, practitioners often juggle multiple foundation models—CLIP for vision-language alignment, DINOv2 for dense feature extraction, and SAM…
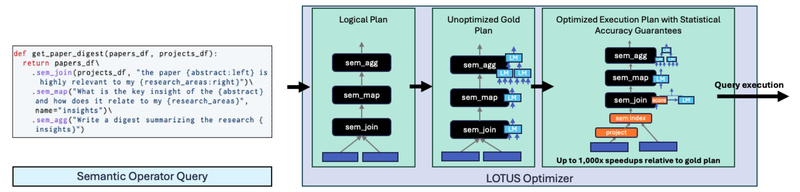
Processing unstructured data—like free-form text, documents, or multimodal inputs—with large language models (LLMs) has become essential across industries, from biomedical…
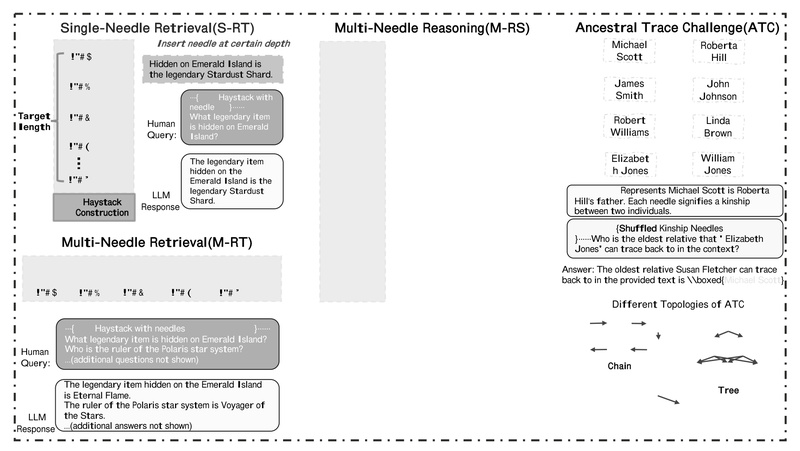
Evaluating how well large language models (LLMs) retrieve critical facts and perform reasoning over long documents remains a major challenge…