Large reasoning models (LRMs)—such as OpenAI’s o1—excel at multi-step logical reasoning, especially in science, math, and code-related tasks. But they…
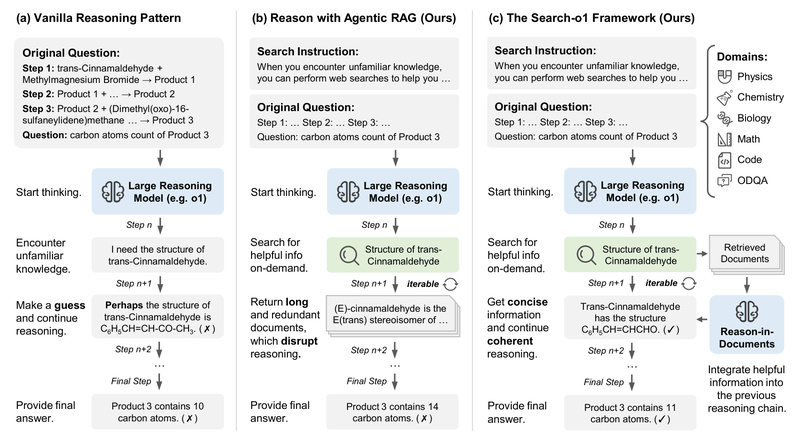
Large reasoning models (LRMs)—such as OpenAI’s o1—excel at multi-step logical reasoning, especially in science, math, and code-related tasks. But they…

Imagine being able to take a single, static video shot on your phone and instantly transform it into a cinematic…
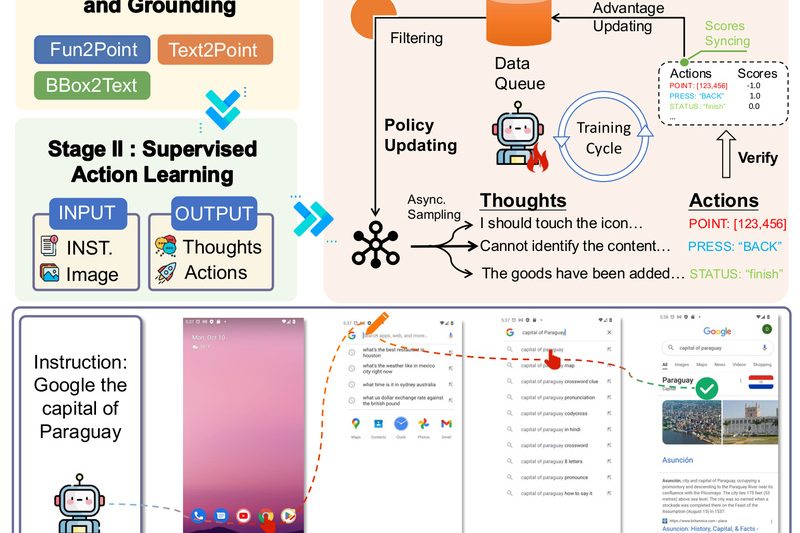
AgentCPM-GUI is an open-source, on-device large language model (LLM) agent designed to understand smartphone screenshots and autonomously perform user-specified tasks…
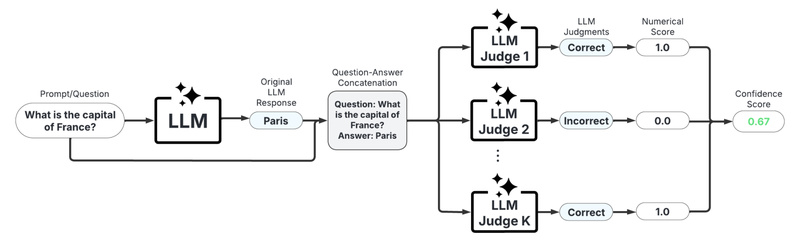
Large Language Models (LLMs) are transforming how we build intelligent applications—from customer service bots to clinical decision support tools. Yet…

Despite massive advances in large language models (LLMs) for coding, a silent crisis persists: debugging remains largely unsolved. Top models…

Parsing complex document images—those containing intertwined text paragraphs, tables, mathematical formulas, figures, and code—is a persistent challenge in applied AI.…
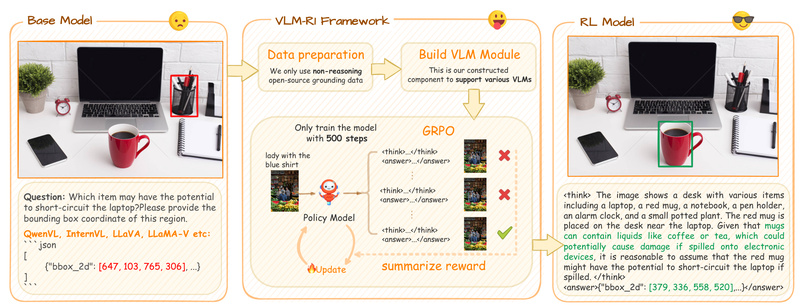
If you’re working on vision-language tasks that require precise reasoning—like identifying objects based on natural language descriptions, detecting UI defects…
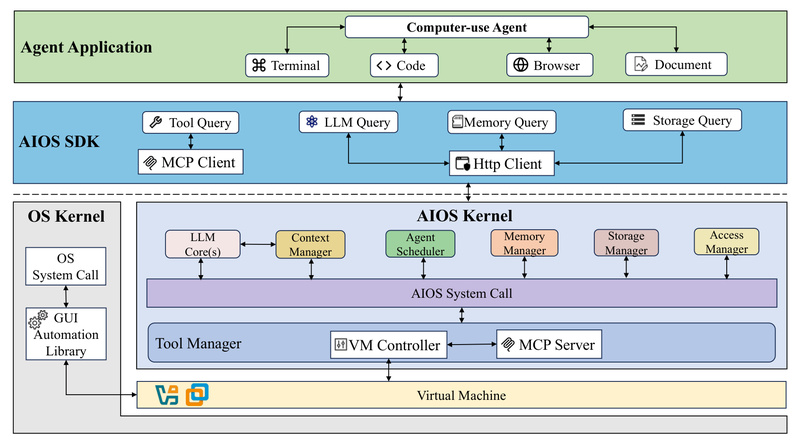
Imagine an AI agent that doesn’t just talk about using a computer—it actually uses one. That’s the promise of LiteCUA,…

Reinforcement learning (RL) has become a cornerstone of modern robotics research, yet many general-purpose RL libraries fall short when it…
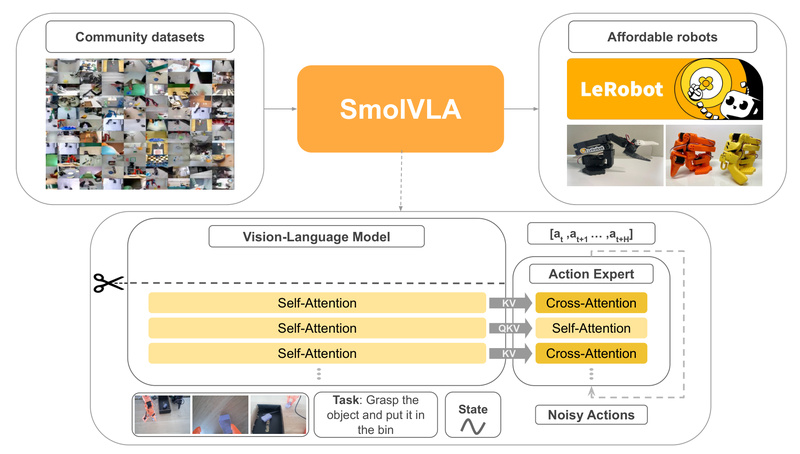
SmolVLA is a compact yet capable Vision-Language-Action (VLA) model designed to bring state-of-the-art robot control within reach of researchers, educators,…