Training large language models and vision architectures is notoriously slow, unstable, and expensive. Practitioners routinely face diminishing returns from standard…
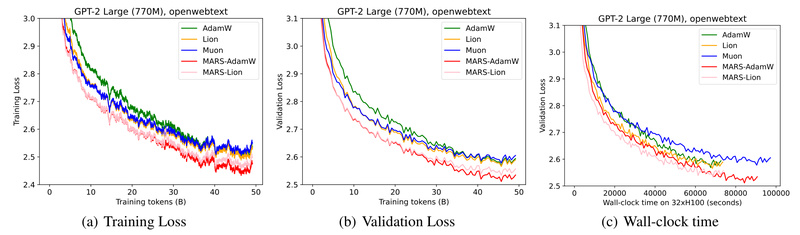
Training large language models and vision architectures is notoriously slow, unstable, and expensive. Practitioners routinely face diminishing returns from standard…
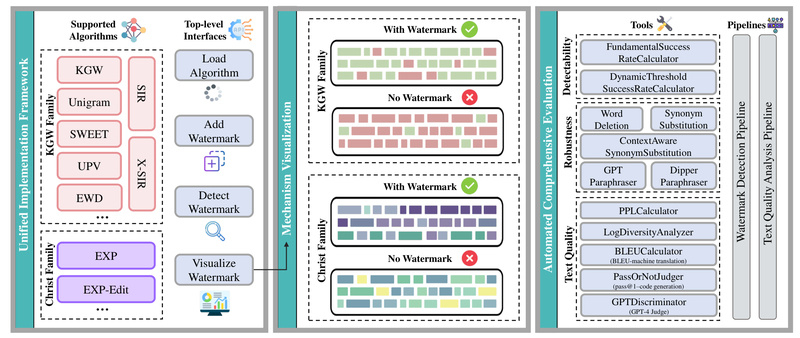
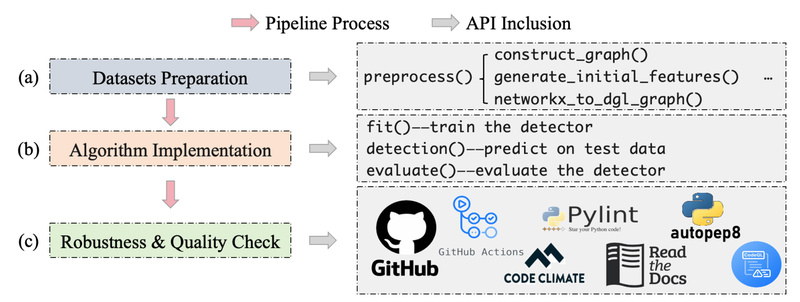
As large language models (LLMs) become deeply embedded in enterprise workflows, content platforms, and research pipelines, the ability to verify…
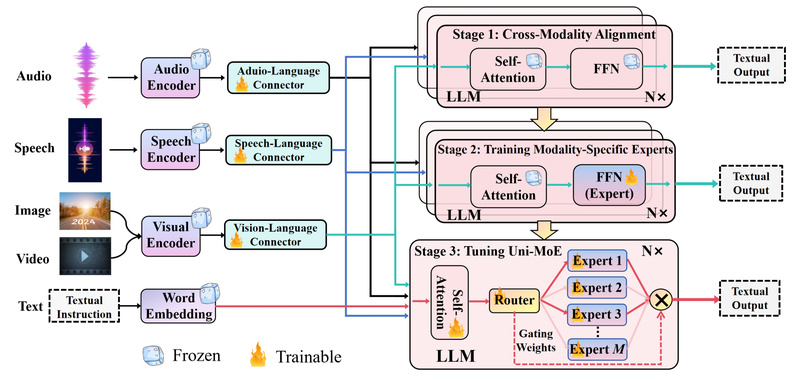
Imagine managing a project that needs to understand speech, analyze images, interpret video frames, and respond to written prompts—all within…
In today’s fast-paced digital landscape, real-time awareness of emerging events—from natural disasters and political rallies to viral misinformation—is critical for…
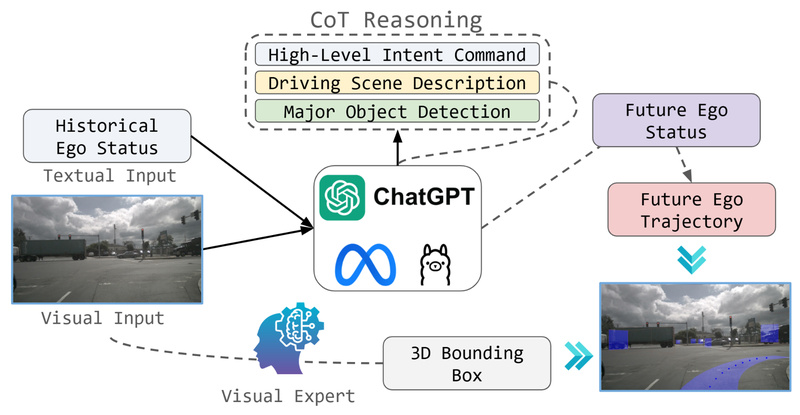
Autonomous driving research has long been bottlenecked by the need for massive datasets, expensive compute infrastructure, and proprietary end-to-end frameworks.…
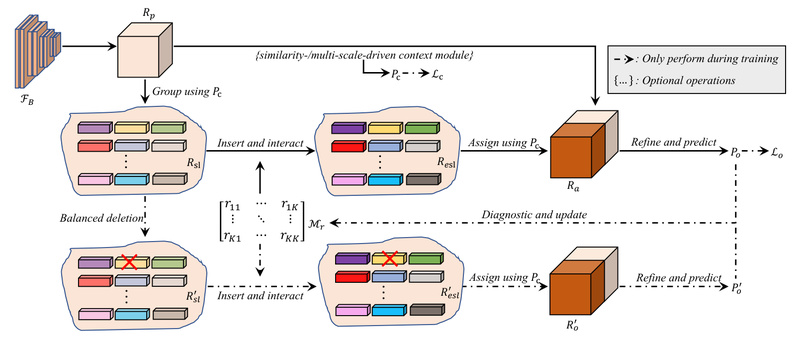
If you’re building computer vision systems that rely on pixel-perfect understanding—like autonomous driving, medical imaging analysis, or retail scene parsing—you’ve…
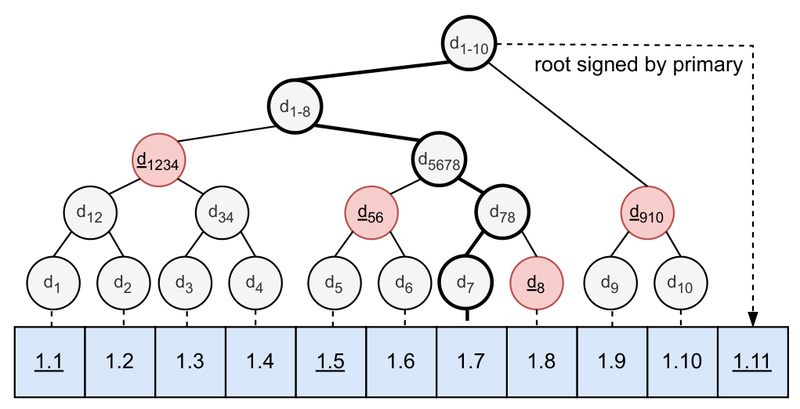
In today’s cloud-first world, organizations increasingly need to collaborate across trust boundaries—whether in finance, healthcare, supply chains, or regulatory compliance.…
Creating realistic, diverse human faces that remain visually consistent with a specific identity—while allowing fine-grained control over expressions—is a persistent…
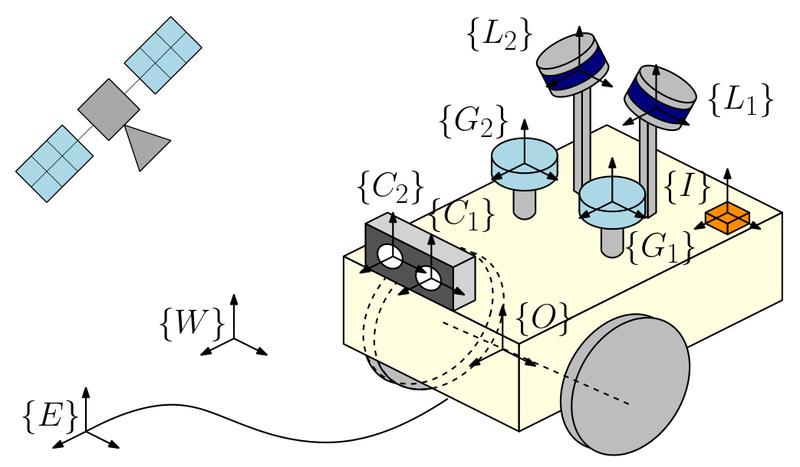
In the world of autonomous systems—whether robots, drones, or self-driving vehicles—accurate and reliable state estimation is non-negotiable. Yet real-world deployments…
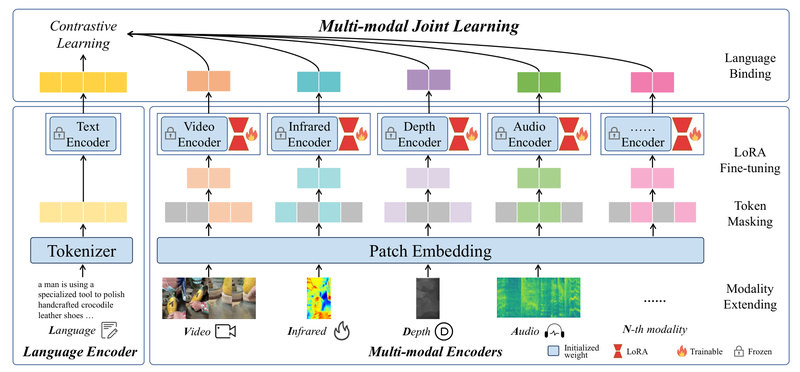
Imagine building an AI system that understands not just images and text—but also video, audio, infrared (thermal), and depth data—all…