If you’ve ever struggled to generate marketing visuals with legible multilingual text—or tried to edit a product image only to…

If you’ve ever struggled to generate marketing visuals with legible multilingual text—or tried to edit a product image only to…

HunyuanImage-3.0 is a groundbreaking open-source image generation model developed by Tencent. Unlike traditional diffusion-based approaches, it builds a native multimodal…

In today’s fast-evolving AI landscape, most generative systems are built for a single task—whether that’s turning text into images, editing…

InstantStyle is a breakthrough framework that enables high-fidelity, style-consistent image generation without requiring any model retraining or per-image tuning. Built…

Modern image generation is powerful—but fragmented. Depending on your goal—generating from text, editing existing images, preserving a person’s identity, or…
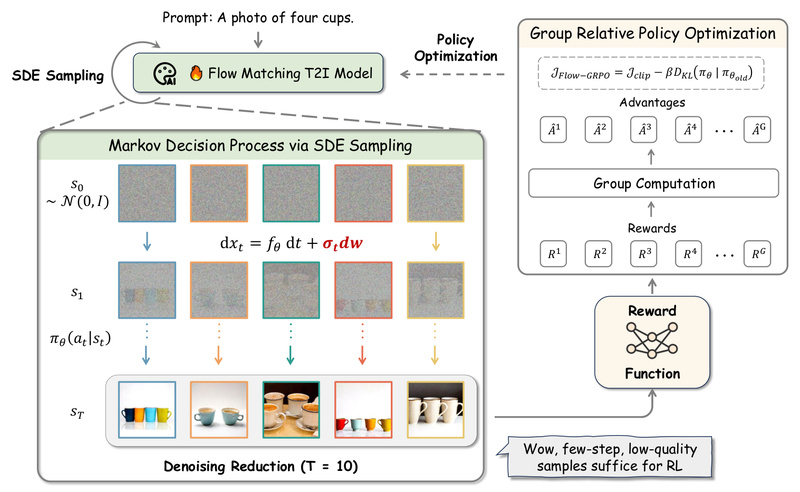
If you’ve ever struggled with diffusion models failing to follow detailed prompts—like “a golden retriever sitting to the left of…

FlowTok reimagines cross-modal generation by collapsing the traditionally complex boundary between text and images into a streamlined, efficient process. Unlike…

In the ever-evolving landscape of generative AI, image synthesis has long been dominated by diffusion models—powerful, yet often complex, resource-intensive,…
If you’ve ever tried using a standard AI image generator to create a poster, product mockup, or social media banner…

OmniGen2 is an open-source, unified generative model that seamlessly bridges text and vision in a single architecture. Unlike many multimodal…