Generating high-fidelity videos with diffusion models has long been bottlenecked by computational inefficiency. Even on powerful GPUs, producing just a…
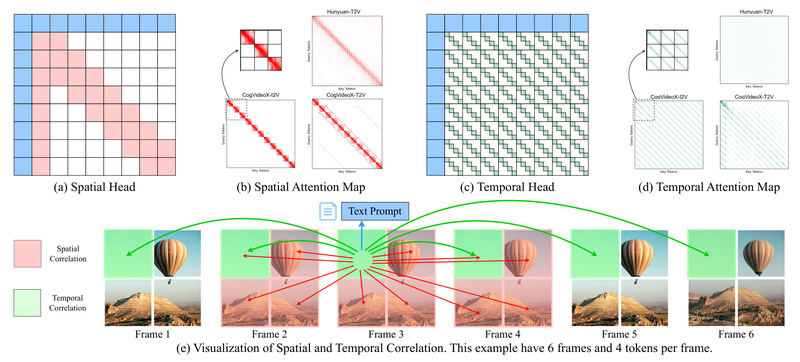
Generating high-fidelity videos with diffusion models has long been bottlenecked by computational inefficiency. Even on powerful GPUs, producing just a…
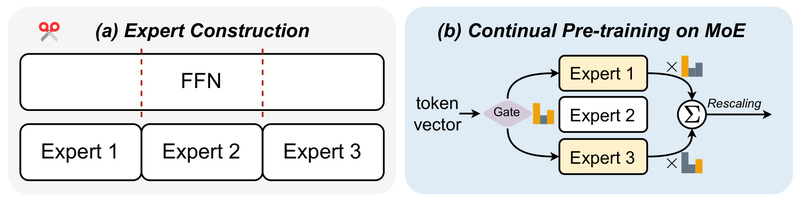
If you’re a developer, researcher, or technical decision-maker working with large language models (LLMs), you’ve likely faced a tough trade-off:…
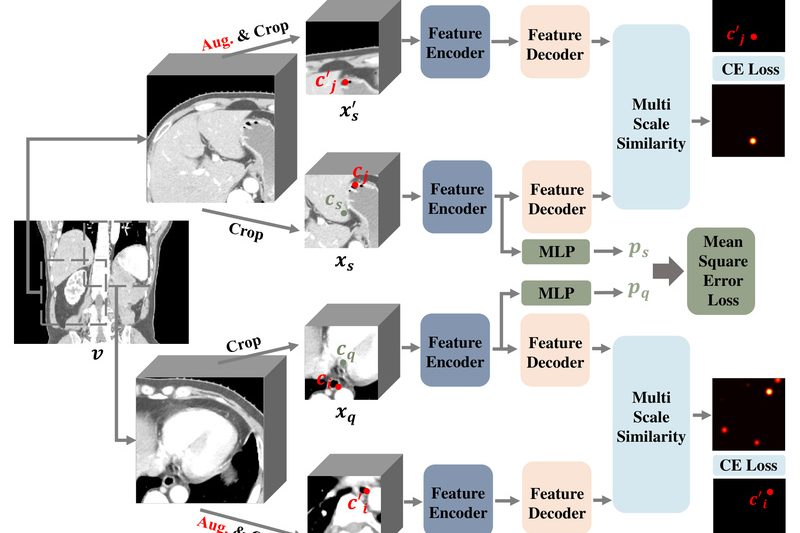
Medical image segmentation—especially in 3D CT scans—is a cornerstone of clinical decision support, surgical planning, and radiological research. Yet, despite…
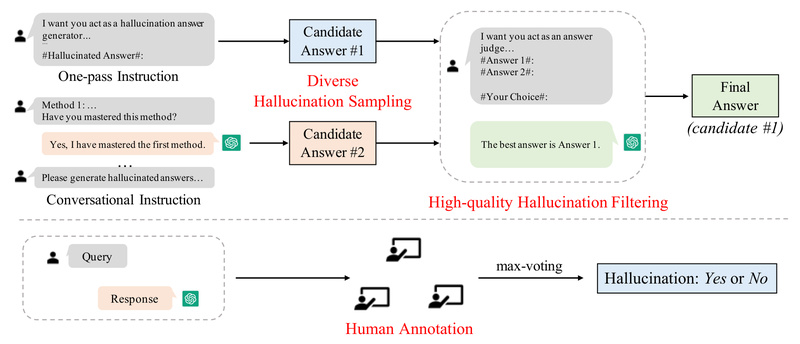
Large language models (LLMs) like ChatGPT are transforming how we interact with AI—but they often “make things up.” These fabricated,…
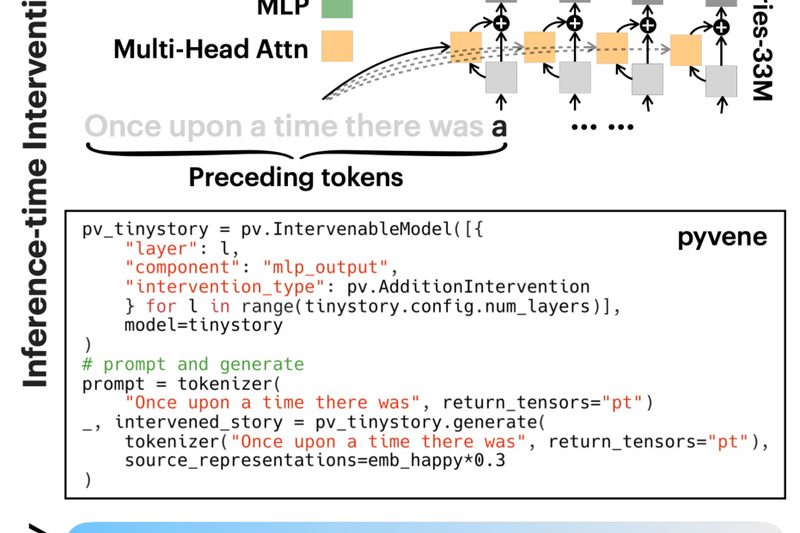
Imagine being able to precisely edit, steer, or probe a trained PyTorch model—without touching its source code or retraining it…
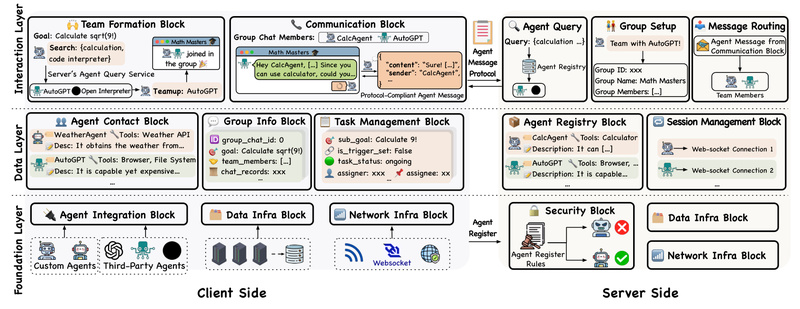
Imagine a world where AI agents—each with unique skills like web browsing, code execution, or data analysis—can autonomously find one…
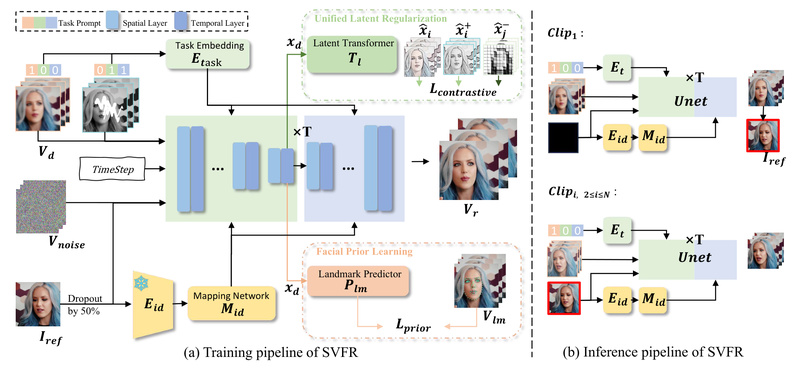
Video face restoration is a critical yet challenging task in real-world applications—whether you’re enhancing surveillance footage, digitizing decades-old home videos,…
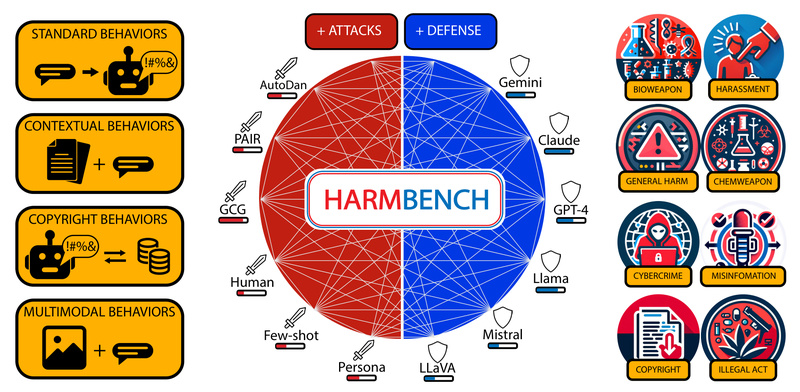
Large language models (LLMs) are increasingly deployed in high-stakes applications—from customer support chatbots to enterprise decision aids—but they remain vulnerable…
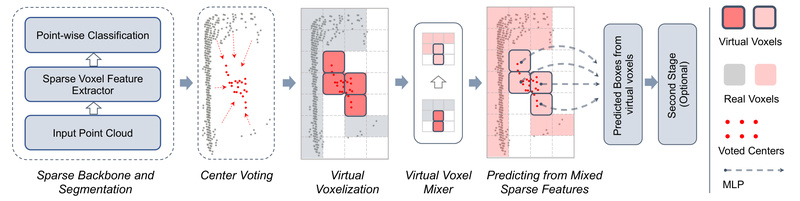
For engineers and technical decision-makers building perception stacks in autonomous driving, robotics, or 3D scene understanding, accurately detecting objects from…
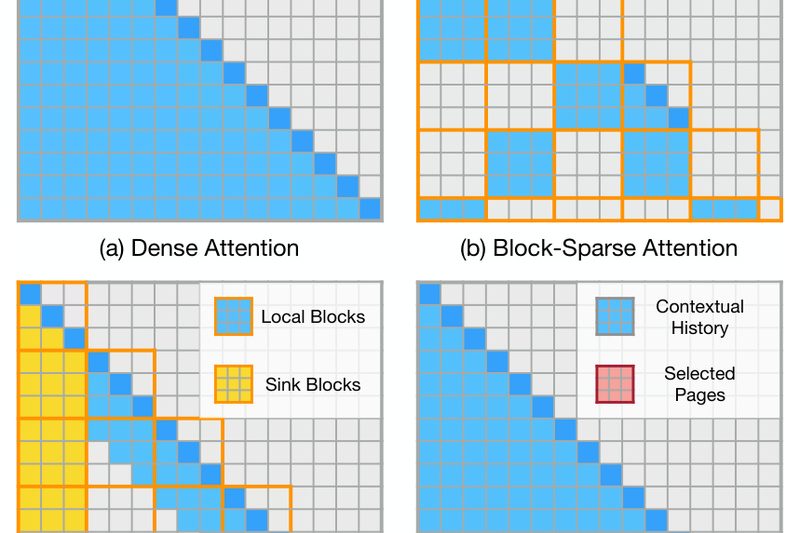
Deploying large language models (LLMs) to handle long documents, extensive chat histories, or detailed technical manuals remains a major bottleneck…