Imagine building an AI system that understands not just images and text—but also video, audio, infrared (thermal), and depth data—all…
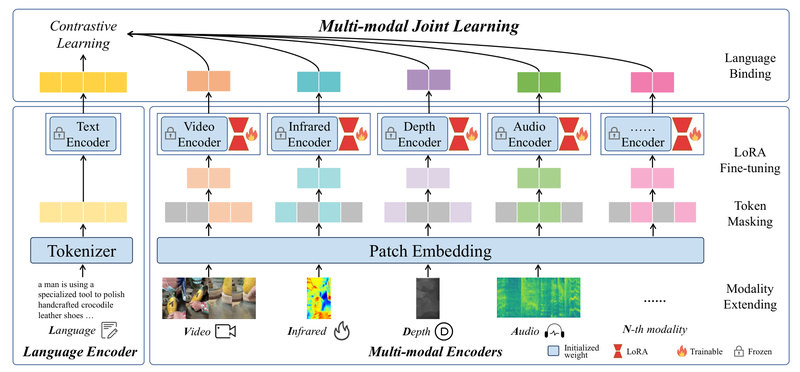
Imagine building an AI system that understands not just images and text—but also video, audio, infrared (thermal), and depth data—all…

Imagine building a system that can understand 3D objects as intuitively as humans do—recognizing a chair from its point cloud,…
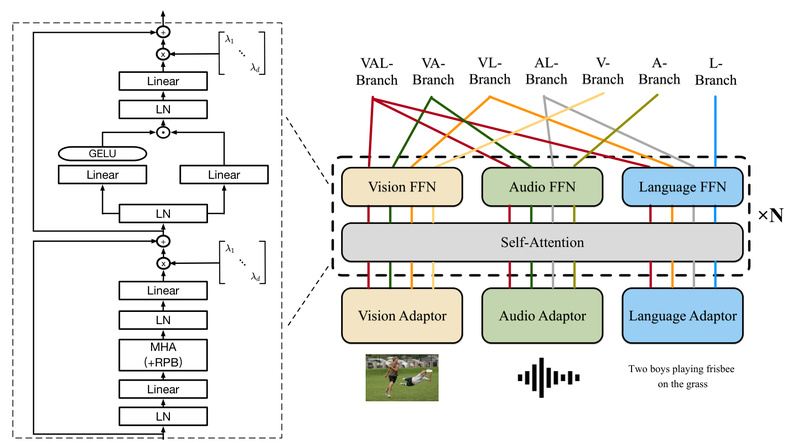
In today’s AI landscape, most multimodal systems are built by stitching together specialized models—separate vision encoders, audio processors, and language…

FlowTok reimagines cross-modal generation by collapsing the traditionally complex boundary between text and images into a streamlined, efficient process. Unlike…